一. 数据抽象:物理抽象、概念抽象、视图级抽象,内模式、模式、外模式
模型是对现实世界的抽象,在数据库技术中,我们用数据模型的概念描述数据库的结构和语义,对现实世界的数据进行抽象。从现实世界的信息到数据库存储的数据以及用户使用的数据是一个逐步抽象的过程,有如下四种:概念数据模型、逻辑数据模型、外部数据模型、和内部数据模型。
1、 概念模型
a) 定义:表达用户需求观点的数据全局逻辑结构的模型
b) 特点:
i. 概念模型表达了数据的整体逻辑结构,它是系统用户对整个应用项目涉及的数据的全面描述;
ii. 概念模型是从用户需求观点出发,对数据建模;
iii. 概念模型独立于硬件和软件;
iv. 概念模型是数据库设计人员与用户之间进行交流的工具。
c) 主要方法:概念模型主要采用的是实体联系(ER)模型,ER模型主要用ER图来表示。
d) ER图:ER图中把研究的对象分成实体和联系两大类,用矩形表示实体类型,菱形表示联系类型,椭圆形表示属性,实体标识符用属性下的一根下划线表示。
e) 优点:
i. 简单,容易理解,真实地反应用户的需求;
ii. 是与计算机无关,用户容易接受。
2、 逻辑模型
a) 定义:表达计算机实现观点的DB全局逻辑结构的模型,选定DBMS后,根据选定的DBMS的特点从概念模型转换成逻辑模型。
b) 特点:
i. 逻辑模型表达了DB的整体逻辑结构,它是设计人员对整个应用项目数据库的全面描述;
ii. 逻辑模型是从数据库实现的观点出发,对数据建模;
iii. 逻辑模型独立于硬件,依赖于软件;
iv. 逻辑模型是数据库设计人员与应用程序员之间交流的工具。
c) 分类:
i. 层次模型(Hierarchical model)
1. 定义:用树形结构表示实体类型及实体间联系的数据模型。
2. 数据联系:指针
3. 数据结构:树结构
4. 优点:记录之间通过指针来实现,查询效率较高
5. 缺点:只能表示1:N联系;由于层次顺序的严格和复杂,引起数据的查询和更新操作很复杂,因此编写程序也很复杂
6. 代表:IMS
7. 盛行:20世纪70年代
ii. 网状模型(Network model)
1. 定义:用有向图结构表示实体类型及实体间联系的数据模型
2. 数据联系:指针
3. 数据结构:有向图结构
4. 优点:记录之间的联系通过指针实现,M:N也较容易实现,查询效率较高
5. 缺点:数据结构复杂和编程复杂
6. 代表:IDS,IMAGE/3000,IDMS,TOTAL
7. 盛行:20世纪70-80年代中期
iii. 关系模型(Relational Model)
1. 定义:用二维表结构表示实体类型及实体间联系的数据模型
2. 数据联系:通过二维表间的公共属性
3. 数据结构:二维表
4. 优点:记录之间的联系采用关键码实现,表格简单,用户易懂;用查询语句就可以实现对数据库操作,不设计存储结构和访问技术
5. 缺点:更复杂的数据结构,如多媒体数据、多维表格数据显得力不从心
6. 代表:Oracle,Sybase,DB2,SQL Server,Infomix
7. 盛行:20世纪80年代到现在
3、 外部模型
a) 定义:表达用户使用观点的DB局部逻辑结构的模型。根据业务的特点划分成若干业务单位,每个业务单位都有特定的约束和需求
b) 特点:
i. 外部模型是逻辑模型的一个逻辑子集;
ii. 外部模型独立于硬件,依赖于软件;
iii. 外部模型反映了用户使用数据库的观点。
c) 优点:
i. 简化了用户的观点;
ii. 有助于数据库的安全性保护;
iii. 外部模型是对概念模型的支持。
4、 内部模型
a) 定义:表达DB物理结构的模型。又称为物理模型,是数据库最底层的抽象,它描述数据在磁盘或磁带上的存储方式,存取设备和存取方法。
b) 特点:
i. 内部模型是与硬件和软件紧密相连的;
ii. 内部模型反映了数据库的底层实现细节。
5、 三层模式和两级映射
a) 三层模式的定义:在用户到数据库之间,DB的数据结构有三个层次外部模型、逻辑模型和内部模型,这个三个层次使用数据定义语言(Data Definition Language,DDL)定义以后就称为模式(Schema),即外模式、逻辑模式和内模式。数据库的数据结构描述有三个层次:
i. 外模式是用户与数据库系统的接口,是用户用到的那部分数据的描述
ii. 逻辑模式是数据库中全部数据的整体逻辑结构的描述
iii. 内模式是数据库在物理存储方面的描述。
b) 三层模式体系结构的特点:
i. 用户使用数据库的数据操纵语言(Data Manipulation Language,DML)语句对数据库进行操作,实际上是对外模式的外部记录进行操作;
ii. 逻辑模式必须不涉及到存储结构、访问技术等细节;
iii. 内模式并不涉及到物理设备的约束。
c) 两级映射的定义:由于三层模式的数据结构可能不一致,即记录类型、字段类型的命名和组成可能不一样,因此需要三层模式之间的映像来说明外部记录、逻辑记录、内部记录之间的对应性。三层模式之间存在两级映像:
i. 外模式/逻辑模式映像存在于外模式和逻辑模式之间,用于定义外模式和逻辑模式之间的对应性,这个映像一般放在外模式中描述
ii. 逻辑模式/内模式映像存在于逻辑模式和内模式之间,用于定义逻辑模式和内模式之间的对应性,这个映像一般放在内模式中描述
d) 飞
6、 数据抽象的过程(即数据库设计的过程)
a) 根据用户需求,设计数据库的概念模型<概念设计>
b) 根据转换规则,把概念模型转换成数据库的逻辑模型
c) 根据用户的业务特点,需根据逻辑模型设计不同的外部模型,给程序员使用,外部模型与逻辑模型之间的对应性称为映像<逻辑设计>
二. SQL语言包括数据定义、数据操纵(Data Manipulation),数据控制(Data Control)
数据定义:Create Table,Alter Table,Drop Table, Craete/Drop Index等
数据操纵:Select ,insert,update,delete,
数据控制:grant,revoke
三. SQL常用命令
CREATE TABLE Student(
ID NUMBER PRIMARY KEY,
NAME VARCHAR2(50) NOT NULL);//建表
CREATE VIEW view_name AS
Select * FROM Table_name;//建视图
Create UNIQUE INDEX index_name ON TableName(col_name);//建索引
INSERT INTO tablename {column1,column2,…} values(exp1,exp2,…);//插入
INSERT INTO Viewname {column1,column2,…} values(exp1,exp2,…);//插入视图实际影响表
UPDATE tablename SET name=’zang 3’ condition;//更新数据
DELETE FROM Tablename WHERE condition;//删除
GRANT (Select,delete,…) ON (对象) TO USER_NAME [WITH GRANT OPTION];//授权
REVOKE (权限表) ON(对象) FROM USER_NAME [WITH REVOKE OPTION] //撤权
列出工作人员及其领导的名字:
Select E.NAME, S.NAME FROM EMPLOYEE E S
WHERE E.SUPERName=S.Name
四. 视图:
什么是视图:
视图(view):从一个或几个基本表中根据用户需要而做成一个虚表
1:视图是虚表,它在存储时只存储视图的定义,而没有存储对应的数据
2:视图只在刚刚打开的一瞬间,通过定义从基表中搜集数据,并展现给用户
视图与查询的区别:
视图和查询都是用由sql语句组成,这是他们相同的地方,但是视图和查询有着本质区别:
它们的区别在于:
1:存储上的区别:视图存储为数据库设计的一部分,而查询则不是.
2:更新限制的要求不一样
要注意:因为视图来自于表,所以通过视图可以间接对表进行更新,我们也可以通过update语句对表进行更新,但是对视图和查询更新限制是不同的,以下我们会知道虽然通过视图可以间接更新表但是有很多限制.
3:排序结果:通过sql语句,可以对一个表进行排序,而视图则不行。比如:创建一个含有order by子句的视图,看一下可以成功吗?
视图的优点:
为什么有了表还要引入视图呢?这是因为视图具有以下几个优点:
1:能分割数据,简化观点。可以通过select和where来定义视图,从而可以分割数据基表中某些对于用户不关心的数据,使用户把注意力集中到所关心的数据列.进一步简化浏览数据工作
2:为数据提供一定的逻辑独立性。 如果为某一个基表定义一个视图,即使以后基本表的内容的发生改变了也不会影响“视图定义”所得到的数据
3:提供自动的安全保护功能。 视图能像基本表一样授予或撤消访问许可权
4:视图可以间接对表进行更新,因此视图的更新就是表的更新
视图的创建和管理
视图的创建
1:通过sql语句
格式:create view 视图名 as select 语句
试一试:分别创建关于一个表或多个表的视图[因为视图可以来自于多表]
2:通过企业管理器
说明:
1:在完成视图的创立之后,就可以像使用基本表一样来使用视图
2:在创建视图时,并非所有的select子查询都可用,如:compute和compute by,order by[除非与top一起连用]
3:但在查询时,依然都可以用在创建时禁用的select子查询
4:在视图创建时,必须为没有标题列指定标题[思考:能否不用select语句来创建一个视图]
视图的删除:
1:通过sql语句:drop view 视图名
2:通过企业管理器
说明:与删除表不同的是,删除视图后只是删除了视图了定义,并没有删除表中的数据.[查看相关性]
修改视图的定义
1:通过企业管理器
2:通过sql语句:
格式:alter view 视图名 as 新的select语句
浏览视图信息 sp_helptext 视图名 [查看视图创建的语句]
如何通过视图修改基本表的数据.
A:在视图上使用insert语句
通过视图插入数据与直接在表中插入数据一样,但视图毕竟不是基本表.因此在进行数据插入时还是有一定的限制
1:如果视图上没有包括基本表中属性为not null[不能为空]的列,那么插入操作会因为那些列是null值而失败.
2:如果某些列因为某些规则或约束的限制而不能直接接受从视图插入的列时,插入会失败
3:如果在视图中包含了使用统计函数的结果,或是包含计算列,则插入操作会失败
4:不能在使用了distinct语句的视图中插入值
5:不能在使用了group by语句的视图中插入值
1
数据库视图介绍(二)
B:使用update更新视图中的数据
1:更新视图与更新表格一样,但是在视图中使用了多个基本表连接的情况下,每次更新操作只能更新来自基本表的一个数据列
例如:创建以下视图:
create view del asselect 职工号,姓名,部门名称,负责人 from work1,部门where work1.部门编号=部门.部门编号
如果再执行下面的语句时:
update del set 职工号=\'001\',部门名称=\'wenda\' where 职工号=\'01\'[出现错误]
只能够改成:
update del set 职工号=\'001\' where 职工号=\'01\' update del set 部门名称=\'wenda\' where 职工号=\'01\'
2:不能在使用了distinct语句的视图中更新值
3:不能在使用了group by语句的视图中更新值
C:使用delete删除视图中数据.
通过视图删除数据最终体现为从基本表中删除数据
格式:delete 视图名 [where 条件]
说明:当视图由两个以上的基表构成时,不允许删除视图的数据
例如:建一个视图kk
create view kk asselect 职工号,姓名,性别,部门名称 from work1,部门 where work1.部门编号=部门.部门编号 [试着去删除]
使用with check option的视图
如果不了解视图定义内容,则常常会发生向视图中输入不符合视图定义的数据的情况.
比如:
create view xm asselect * from work where 性别=\'男\'
完全可以插入insert xm values(\'001\',\'女\',23,\'2400\'....)
尽管从意义上来说是不合理的,但是上述语句是正确的.为了防止这种情况的发生,可以使用with check option子句来对插入的或更改的数据进行限制.
比如:
create view xm asselect * from work where 性别=\'男\' with check option
使用schemabinding的视图[使用绑定到构架]
我们知道视图是依赖于表,如果在一个表中创建一个视图,今后如果这个表被删除了,则这个视图将不可再用了.为了防止用户删除一个有视图在引用的表,可以在创建视图的时候加上schemabinding关键字.
比如:
create view 基本工资 with SCHEMABINDINGas select 姓名,性别,基本工资 from dbo.work
说明:
1:不能使用“*”来创建此类型的视图
2:创建此类型的视图时,一定要加上dbo.表名.
3:如果在某个表中定义了此类视图,则用户将不能对表的结构进行修改,否则会删除这些绑定
4:如果用户对表的结构进行列改名,则会删除绑定而且视图不可用.
5:如果用户对表的结构进行列的类型或者大小修改,则会删除绑定但视图可用,此时用户可以删除视图所引用的表.
使用with encryption对视图进行加密
为了保护创建视图定义的原代码,可以对视图进行加密.
比如:
create view kk with encryptionas select * from work where 职称=\'经理\'
用sp_helptext来查看一下.或用企业管理器查看一下.
说明:如果应用此项用户将无法设计视图
使用视图加强数据的安全
一般通过使用视图共有三种途径加强数据的安全性
A:对不同用户授予不同的使用权.
B:通过使用select子句限制用户对某些底层基表的列的访问
C:通过使用where子句限制用户对某些底层基表的行的访问, 对不同用户授予不同的权限
五. 完整性约束:实体完整性、参照完整性、用户定义完整性
六. 第三范式:
1NF:每个属性是不可分的。
2NF:若关系R是1NF,且每个非主属性都完全函数依赖于R的键。例SLC(SID#, CourceID#, SNAME,Grade),则不是2NF;
3NF:若R是2NF,且它的任何非键属性都不传递依赖于任何候选键。
7. ER(实体/联系)模型
引言:数据库设计 Step by Step (2)在园子里发表之后,收到了一些邮件,还有朋友直接电话我询问为什么不包含数据库物理设计方面的内容。我在这里解释一下,数据库物理设计与数据库产品是密切相关的,本系列的专注点是较为通用的数据库设计理念与方法,这也是国内软件项目中容易被忽视的一块。今天我们将学习实体关系(ER)模型构件及其语义,这是数据库逻辑设计的基础。内容可能有些枯燥,但却非常重要和有用。
由于内容比较多,我们将分两讲来学习实体关系模型构件。
今天我们先来学习基本实体关系模型。
实体关系(ER)模型的目标是捕获现实世界的数据需求,并以简单、易理解的方式表现出来。ER模型可用于项目组内部交流或用于与用户讨论系统数据需求。
ER模型中的基本元素
基本的ER模型包含三类元素:实体、关系、属性
图1 实体、关系、属性的ER构图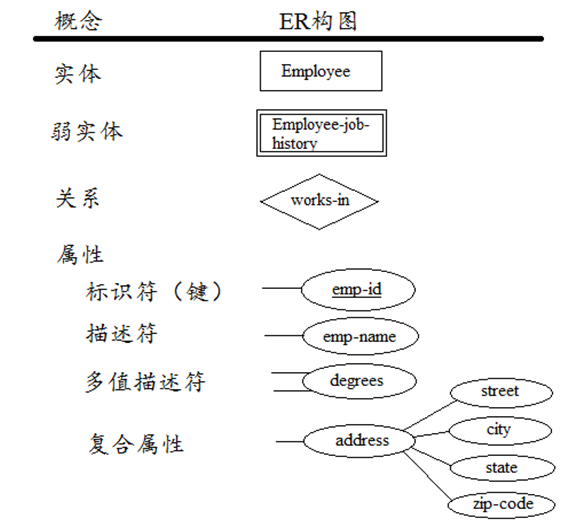
实体(Entities):实体是首要的数据对象,常用于表示一个人、地方、某样事物或某个事件。一个特定的实体被称为实体实例(entity instance或entity occurrence)。实体用长方形框表示,实体的名称标识在框内。一般名称单词的首字母大写。
关系(Relationships):关系表示一个或多个实体之间的联系。关系依赖于实体,一般没有物理概念上的存在。关系最常用来表示实体之间,一对一,一对多,多对多的对应。关系的构图是一个菱形,关系的名称一般为动词。关系的端点联系着角色(role)。一般情况下角色名可以省略,因为实体名和关系名已经能清楚的反应角色的概念,但有些情况下我们需标出角色名来避免歧义。
属性(Attributes):属性为实体提供详细的描述信息。一个特定实体的某个属性被称为属性值。Employee实体的属性可能有:emp-id, emp-name, emp-address, phone-no……。属性一般以椭圆形表示,并与描述的实体连接。属性可被分为两类:标识符(identifiers),描述符(descriptors)。Identifiers可以唯一标识实体的一个实例(key),可以由多个属性组成。ER图中通过在属性名下加上下划线来标识。多值属性(multivalued attributes)用两条线与实体连接,eg:hobbies属性(一个人可能有多个hobby,如reading,movies…)。复合属性(Complex attributes)本身还有其它属性。
辨别强实体与弱实体:强实体内部有唯一的标识符。弱实体(weak entities)的标识符来自于一个或多个其它强实体。弱实体用双线长方形框表示,依赖于强实体而存在。
深入理解关系
关系在ER模型中扮演了非常重要的角色。通过ER图可以描述实体间关系的度、连通数、存在性信息。
我们一一来解释这些概念。首先我们来看一下关系在ER图中的各种语义。
图2 关系的度、连通数、存在性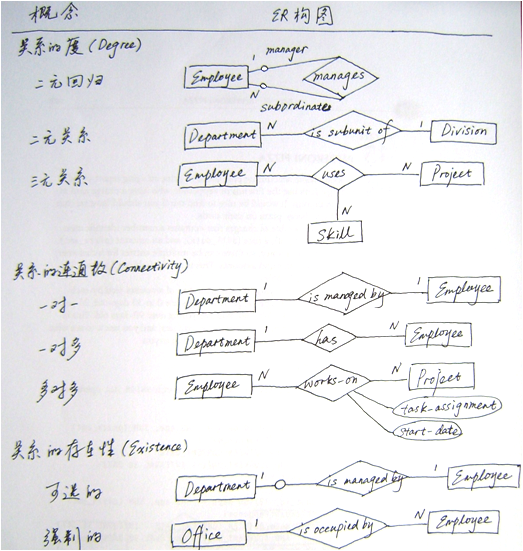
关系的度(Degree of a Relationship)
表示关系所关联的实体数量。二元关系与三元关系的度分别为2和3,以此可以类推至n元。二元关系是最常见的关系。
一个Employee与另一个Employee之间的领导关系称为二元回归关系。如图2中所示,Employee实体通过关系manages与自身连接。由于Employee在这一关系中扮演两个角色,故标出了角色名(manager和subordinate)。
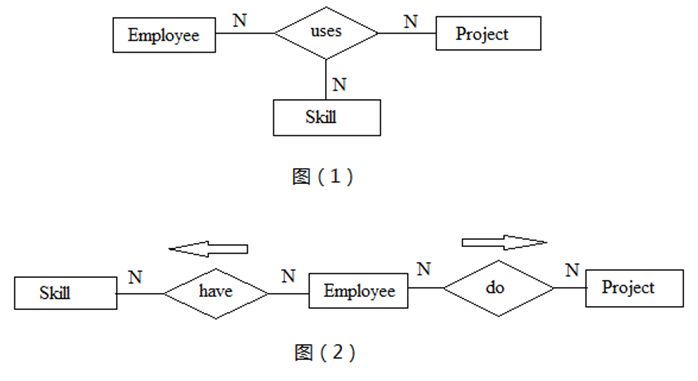
三元关系联系三个实体。当二元关系无法准确描述关联的语义时,就需要使用三元关系。我们来看下面这个例子,下图(1)能反映出一个Employee在某个Project中使用了什么Skill。下图(2)只能看出Employee有什么Skill,参与了哪些Project,但无法知道在某个Project中使用的特定Skill。
图3 三元关系蕴含的语义需要注意的是有些情况下会错误的定义三元关系。这些三元关系可分解为2个或3个二元关系,来达到化简与语义的纯净。以后的博文中会进一步详细讨论三元关系。
一个实体可以参与到任意多个关系中。每个关系可以联系任意多个元(实体),而且两个实体之间也能有任意多个二元关系。
关系的连通数(Connectivity of a Relationship)
表示关系所关联的实例数量的约束。
连通数的值可以是“一”或“多”。“一”这一端,在ER图中通过在实体与关系间标记“1”表示。“多”一端标记“N”表示。如图2中关系连通数部分,“一”对“一”:Department is managed by Employee;“一”对“多”:Department has Employees;“多”对“多”:Employee may work on many Projects and each Project may have many Employees。
有些情况下最大连通数是确定的,可以用数值代替N。如:田径队队员有12人。
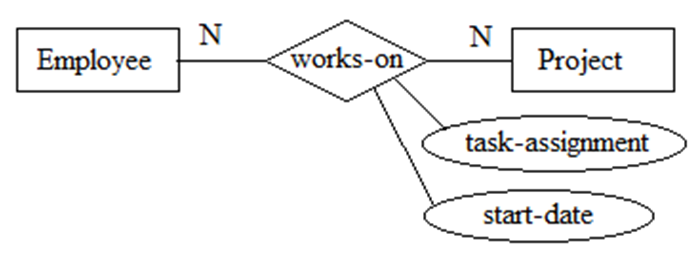
关系的属性
关系也能有属性。如下图4所示,某员工参与某项目的起始日期,某员工在某项目中被分配的任务只有放在关系works-on上才有意义。
图4 关系的属性需要注意的是关系的属性一般出现在“多”对“多”的二元关系或三元关系上。一般“一”对“一”或“一”对“多”关系上不会放属性(会引起歧义)。而且这些属性可以移至一端的实体中。如下图5所示,如果部门与员工(经理)之间是“一”对“一”关系,在建模中可能把start-date作为关系is managed by的属性(表示被接管的时间),这个属性可以移至Department或Employee实体中。
图5 部门与经理之间的一对一管理关系大家可以思考一下如果部门和经理之间是“多”对“多”关系,即交叉管理,那又会怎样?
关系中实体的存在性(Existence of an Entity in a Relationship)
关系中实体的存在性可以是强制的或可选的。当关系中的某一边实体(无论是“一”或“多”端)必须总是存在,则该实体为强制的。反之,该实体为可选的。
在实体与关系之间的连接线上标识“0”来表示可选存在性。含义是最小连通数为0。
强制存在性表示最小连通数为1。在存在性不确定或不可知的情况下,默认最小连通数为1。
在ER图中最大连通数显式地标识在实体旁边。如图6所示,其蕴含的语义为一个Department有且只有一个Employee来当经理,一个Employee可能是一个Department的经理,也可能不是。
图6 关系中实体的存在性
其他概念数据模型标记法
前文中使用的ER构图方法是Peter Chen 1976年提出的。在现代数据库设计领域,还有其他多种ER模型标记法。
我们来看一下另一种使用较多的标记法,“crow’s-foot”(鱼尾纹)标记法,并与前面介绍的标记法进行一个简单对比。
学习每一种标记法没有意义。在你的组织中推广应用一种标记法,使其成为大家共通的“语言”。
图7 Chen式标记法与crow’s-foot标记法对照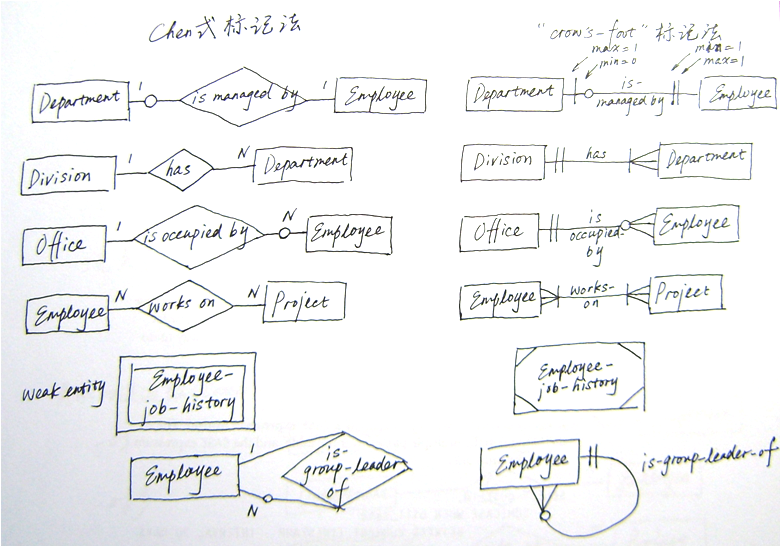
八. 索引作用
为什么要创建索引呢?这是因为,创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快 数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序 子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?这种想法固然有其合理性,然而也有其片面性。虽然,索引有许多优点, 但是,为表中的每一个列都增加索引,是非常不明智的。这是因为,增加索引也有许多不利的一个方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据 量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引是建立在数据库表中的某些列的上面。因此,在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列 上创建索引,例如:
在经常需要搜索的列上,可以加快搜索的速度;
在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因 为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那 些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比 例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索 引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因 此,当修改性能远远大于检索性能时,不应该创建索引。
创建索引的方法和索引的特征
创建索引的方法
创建索引有多种方法,这些方法包括直接创建索引的方法和间接创建索引的方法。直接创建索引,例如使用CREATE INDEX语句或者使用创建索引向导,间接创建索引,例如在表中定义主键约束或者唯一性键约束时,同时也创建了索引。虽然,这两种方法都可以创建索引,但 是,它们创建索引的具体内容是有区别的。
使用CREATE INDEX语句或者使用创建索引向导来创建索引,这是最基本的索引创建方式,并且这种方法最具有柔性,可以定制创建出符合自己需要的索引。在使用这种方式 创建索引时,可以使用许多选项,例如指定数据页的充满度、进行排序、整理统计信息等,这样可以优化索引。使用这种方法,可以指定索引的类型、唯一性和复合 性,也就是说,既可以创建聚簇索引,也可以创建非聚簇索引,既可以在一个列上创建索引,也可以在两个或者两个以上的列上创建索引。
通过定义主键约束或者唯一性键约束,也可以间接创建索引。主键约束是一种保持数据完整性的逻辑,它限制表中的记录有相同的主键记录。在创建主键约束时,系 统自动创建了一个唯一性的聚簇索引。虽然,在逻辑上,主键约束是一种重要的结构,但是,在物理结构上,与主键约束相对应的结构是唯一性的聚簇索引。换句话 说,在物理实现上,不存在主键约束,而只存在唯一性的聚簇索引。同样,在创建唯一性键约束时,也同时创建了索引,这种索引则是唯一性的非聚簇索引。因此, 当使用约束创建索引时,索引的类型和特征基本上都已经确定了,由用户定制的余地比较小。
当在表上定义主键或者唯一性键约束时,如果表中已经有了使用CREATE INDEX语句创建的标准索引时,那么主键约束或者唯一性键约束创建的索引覆盖以前创建的标准索引。也就是说,主键约束或者唯一性键约束创建的索引的优先 级高于使用CREATE INDEX语句创建的索引。
索引的特征
索引有两个特征,即唯一性索引和复合索引。
唯一性索引保证在索引列中的全部数据是唯一的,不会包含冗余数据。如果表中已经有一个主键约束或者唯一性键约束,那么当创建表或者修改表时,SQL Server自动创建一个唯一性索引。然而,如果必须保证唯一性,那么应该创建主键约束或者唯一性键约束,而不是创建一个唯一性索引。当创建唯一性索引 时,应该认真考虑这些规则:当在表中创建主键约束或者唯一性键约束时,SQL Server自动创建一个唯一性索引;如果表中已经包含有数据,那么当创建索引时,SQL Server检查表中已有数据的冗余性;每当使用插入语句插入数据或者使用修改语句修改数据时,SQL Server检查数据的冗余性:如果有冗余值,那么SQL Server取消该语句的执行,并且返回一个错误消息;确保表中的每一行数据都有一个唯一值,这样可以确保每一个实体都可以唯一确认;只能在可以保证实体 完整性的列上创建唯一性索引,例如,不能在人事表中的姓名列上创建唯一性索引,因为人们可以有相同的姓名。
复合索引就是一个索引创建在两个列或者多个列上。在搜索时,当两个或者多个列作为一个关键值时,最好在这些列上创建复合索引。当创建复合索引时,应该考虑 这些规则:最多可以把16个列合并成一个单独的复合索引,构成复合索引的列的总长度不能超过900字节,也就是说复合列的长度不能太长;在复合索引中,所 有的列必须来自同一个表中,不能跨表建立复合列;在复合索引中,列的排列顺序是非常重要的,因此要认真排列列的顺序,原则上,应该首先定义最唯一的列,例 如在(COL1,COL2)上的索引与在(COL2,COL1)上的索引是不相同的,因为两个索引的列的顺序不同;为了使查询优化器使用复合索引,查询语 句中的WHERE子句必须参考复合索引中第一个列;当表中有多个关键列时,复合索引是非常有用的;使用复合索引可以提高查询性能,减少在一个表中所创建的 索引数量。
9. 事务:
是一系列的数据库操作,是数据库应用的基本逻辑单位。事务性质:原子性、
原子性。即不可分割性,事务要么全部被执行,要么就全部不被执行。
一致性或可串性。事务的执行使得数据库从一种正确状态转换成另一种正确状态
隔离性。在事务正确提交之前,不允许把该事务对数据的任何改变提供给任何其他事务,
持久性。事务正确提交后,其结果将永久保存在数据库中,即使在事务提交后有了其他故障,事务的处理结果也会得到保存。
10. 锁:共享锁、互斥锁
两段锁协议:阶段1:加锁阶段 阶段2:解锁阶段
11. 死锁及处理:
事务循环等待数据锁,则会死锁。
死锁处理:预防死锁协议,死锁恢复机制
12. 存储过程:
存储过程就是编译好了的一些sql语句。
a.存储过程因为SQL语句已经预编绎过了,因此运行的速度比较快。
b. 可保证数据的安全性和完整性。通过存储过程可以使没有权限的用户在控制之下间接地存取数据库,从而保证数据的安全。通过存储过程可以使相关的动作在一起发生,从而可以维护数据库的完整性。
c.可以降低网络的通信量。存储过程主要是在服务器上运行,减少对客户机的压力。
d:存储过程可以接受参数、输出参数、返回单个或多个结果集以及返回值。可以向程序返回错误原因
e:存储过程可以包含程序流、逻辑以及对数据库的查询。同时可以实体封装和隐藏了数据逻辑。
13. 触发器:
当满足触发器条件,则系统自动执行触发器的触发体。
触发时间:有before,after.触发事件:有insert,update,delete三种。触发类型:有行触发、语句触发
14.内联接,外联接区别?
内连接是保证两个表中所有的行都要满足连接条件,而外连接则不然。
在外连接中,某些不满条件的列也会显示出来,也就是说,只限制其中一个表的行,而不限制另一个表的行。分左连接、右连接、全连接三种
内连接:把两个表中数据对应的数据查出来
外连接:以某个表为基础把对应数据查出来(全连接是以多个表为基础)
student表
no name
1 a
2 b
3 c
4 d
grade表
no grade
1 90
2 98
3 95
内连接 inner join(查找条件中对应的数据,no4没有数据不列出来)
语法:select * from student inner join grade on student.no = grade.no
结果
student.no name grade.no grade
1 a 1 90
2 b 2 98
3 c 3 95
左连接(左表中所有数据,右表中对应数据)
语法:select * from student left join grade on student.no = grade.no
结果:
student.no name grade.no grade
1 a 1 90
2 b 2 98
3 c 3 95
4 d
右连接(右表中所有数据,左表中对应数据)
语法:select * from student right join grade on student.no = grade.no
结果:
student.no name grade.no grade
1 a 1 90
2 b 2 98
3 c 3 95
全连接
语法:select * from student full join grade on student.no = grade.no
结果:
no name grade
1 a 90
2 b 98
3 c 95
4 d
1 a 90
2 b 98
3 c 95
理解Oracle的各种连接方法的最有效的方法就是“躬亲”,在实践中去深刻理解内连接,左外连接,右外连接,全外连接的概念的和效果。
1.创建测试表并准备测试数据
sec@ora10g> create table a (a number(1),b number(1),c number(1));
sec@ora10g> create table b (a number(1),d number(1),e number(1));
sec@ora10g> insert into a values(1,1,1);
sec@ora10g> insert into a values(2,2,2);
sec@ora10g> insert into a values(3,3,3);
sec@ora10g> insert into b values(1,4,4);
sec@ora10g> insert into b values(2,5,5);
sec@ora10g> insert into b values(4,6,6);
sec@ora10g> commit;
sec@ora10g> select * from a;
A B C
---------- ---------- ----------
1 1 1
2 2 2
3 3 3
sec@ora10g> select * from b;
A D E
---------- ---------- ----------
1 4 4
2 5 5
4 6 6
2. 内连接
sec@ora10g> select * from a, b where a.a=b.a;
另外一种写法如下
sec@ora10g> select * from a inner join b on a.a=b.a;
A B C A D E
---------- ---------- ---------- ---------- ---------- ----------
1 1 1 1 4 4
2 2 2 2 5 5
3.左外连接
sec@ora10g> select * from a,b where a.a=b.a(+);
另外一种写法如下
sec@ora10g> select * from a left outer join b on a.a=b.a;
A B C A D E
---------- ---------- ---------- ---------- ---------- ----------
1 1 1 1 4 4
2 2 2 2 5 5
3 3 3
4.右外连接
sec@ora10g> select * from a,b where a.a(+)=b.a;
另外一种写法如下
sec@ora10g> select * from a right outer join b on a.a=b.a;
A B C A D E
---------- ---------- ---------- ---------- ---------- ----------
1 1 1 1 4 4
2 2 2 2 5 5
4 6 6
5.全外连接
sec@ora10g> select * from a full outer join b on a.a=b.a;
A B C A D E
---------- ---------- ---------- ---------- ---------- ----------
1 1 1 1 4 4
2 2 2 2 5 5
3 3 3
4 6 6
6.小结
通过使用Oracle提供的各种SQL连接功能可以解决诸多的“疑难杂症”,需灵活掌握。
2、你用过 Prepared statement( 预处理语句 )? 它的作用是什么 ? 3、什么叫做数据库事务,请举例说明用法.4、Java中访问数据库的步骤,Statement和PreparedStatement之间的区别5、存储过程和函数的区别.6、游标的作用?如何知道游标已经到了最后?7、触发器分为事前触发和事后触发,这两种触发有和区别。语句级触发和行级触发有何区别8、给你一个:驱动程序A,数据源名称为B,用户名称为C,密码为D,数据库表为T,请用JDBC检索出表T的所有数据。9、Class.forName的作用?为什么要用?10、内连接与外联结的区别11、Oracle中查询前几条记录12、某一表经常死锁,分析其原因以及解决方案13、如果网易通行证现在有1亿用户,怎么样解决登录缓慢问题.14、分页怎么实现的,你在项目中怎么用的,都有什么参数
作者:chenchun
联系客服