
WinBUGS在统计分析中的应用
开篇词
首先非常感谢COS论坛提供了这样一个良好的平台,敝人心存感激之余,也打算把一些学习心得拿出来供大家分享,文中纰漏之处还请各位老师指正。下面我将以WinBUGS的统计应用为题,分几次来谈一谈WinBUGS这个软件。其中会涉及到空间数据的分析、GeoBUGS的使用、面向R及SPLUS的接口包R2WinBUGS的使用、GIS与统计分析等等衍生出的话题。如有问题,请大家留下评论,我会调整内容,择机给予回答。
第一节什么是WinBUGS?
WinBUGS对于研究Bayesian统计分析的人来说,应该不会陌生。至少对于MCMC方法是不陌生的。WinBUGS(Bayesian inference Using GibbsSampling)就是一款通过MCMC方法来分析复杂统计模型的软件。其基本原理就是通过Gibbssampling和Metropolis算法,从完全条件概率分布中抽样,从而生成马尔科夫链,通过迭代,最终估计出模型参数。引入Gibbs抽样与MCMC的好处是不言而喻的,就是想避免计算一个具有高维积分形式的完全联合后验概率公布,而代之以计算每个估计参数的单变量条件概率分布。具体的算法思想,在讲到具体问题的时候再加以叙述,在此不过多论述。就不拿公式出来吓人了(毕竟打公式也挺费劲啊)。
第二节为什么要用WinBUGS?
第一、因为同类分析软件中它做得最好。同类的软件:OpenBUGS、JAGS等在成熟度、灵活性以及兼容性方面和它相比还有一定距离。在处理spatialda
第二、因为它免费。免费的东西总有吸引人之处。
第三、有各色的R包为WinBUGS实现了针对R的、SPLUS的、Matlab的软件接口。只要你喜欢,就直接在R下调用WinBUGS吧,无非是装个R2WinBUGS包,简简单单。
第四、详细的文档、帮助、指导、范例。当然没有中文版的,小小一点遗憾。
第三节如何得到WinBUGS?
WinBUGS目前是一款免费的软件,去http://www.mrc-bsu.cam.ac.uk/bugs/下载就好了。不过要用高级功能(如GeoBUGS)的话,还是去http://www.mrc-bsu.cam.ac.uk/bugs/winbugs/contents.shtml注册一下好了,挺方便的。系统会立即把注册码发到你邮箱(真是好人啊)。不过只可以用一个月。这倒无妨,到时在注册一下就好了。
第四节初试WinBUGS
WinBUGS-GUI
我们先找一个例子来实际地运行一下WinBUGS,感受一下基本的操作流程,然后再考虑高级的操作。
第一步,打开WinBUGS,通过菜单File-> New新建一个空白的窗口
第二步,在第一步中新建的空白窗口中输入三部分内容:模型定义、数据定义、初始值定义(代码见附录)
第三步,点击菜单Model-> Specification,弹出一个SpecificationTool面板。
第四步,在第二步中的提到的那个窗口中,将model这个关键字高亮起来,点击checkmodel。你会看到WinBUGS的左下角状态栏上显示”model is syntacticallycorrect.”
第五步,把定义的da
第六步,改SpecificationTool面板上的马尔科夫链的数目,默认为1就好了
第七步,点击SpecificationTool面板上的compile
第八步,把定义的初始值中的list关键字也高亮起来,再点击SpecificationTool面板上的load inits
第九步,关了SpecificationTool面板
第十步,点击菜单Inference-> Samples,弹出一个Sample Monitor Tool面板。
第十一步,在Sample MonitorTool面板的node中填要估计的参数名,这里可以是tau, alpha0, alpha1, b,把它们一个一个填在node中,逐一点set。
第十二步,关了Sample MonitorTool面板
第十三步,点击菜单Model-> Update,弹出一个Update Tool面板。
第十四步,将UpdateTool面板中的updates改大点,比如50000,点update按钮。
第十五步,运行完后,关了UpdateTool面板
第十六步,点击菜单Inference-> Samples
第十七步,在弹出的SampleMonitor Tool面板上选一个node
第十八步,点history看所有迭代的时间序列图,点trace看最后一次迭代的时间序列图,点autocor看correlogram时间序列图,点stat看参数估计的结果
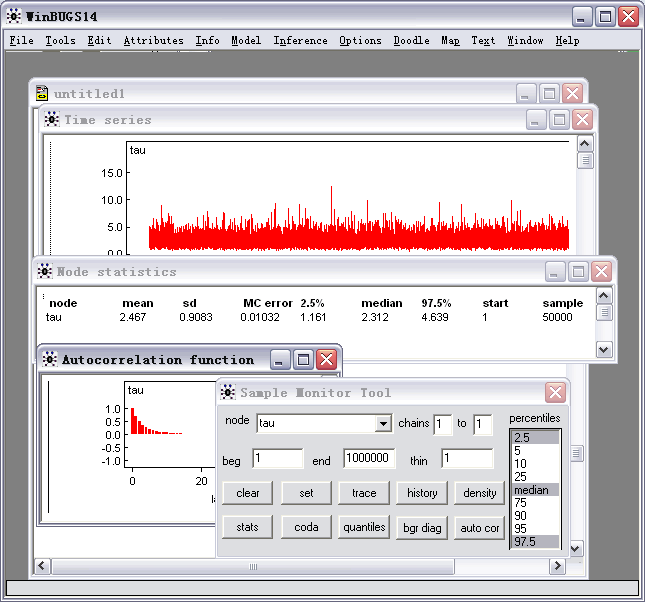
Estimation results byWinBUGS 1.4
附第二步中的代码如下:
#MODELmodel{ for (iin 1:N) { O[i] ~ dpois(mu[i]) log(mu[i]) <-log(E[i]) + alpha0 + alpha1 * X[i]/10 + b[i] # Area-specificrelative risk (for maps) RR[i] <- exp(alpha0 +alpha1 * X[i]/10 + b[i]) } # CAR prior distribution for randomeffects: b[1:N] ~ car.normal(adj[], weights[], num[], tau) for (kin 1:sumNumNeigh) { weights[k] <- 1 } # Otherpriors: alpha0 ~ dflat() alpha1 ~ dnorm(0, 1e-05) tau ~ dgamma(0.5,5e-04) # prior on precision sigma <- sqrt(1/tau) #standard deviation}#DATAlist(N = 56, O = c(9, 39, 11, 9, 15, 8, 26,7, 6, 20, 13, 5, 3, 8, 17, 9, 2, 7, 9, 7, 16, 31, 11, 7, 19, 15, 7,10, 16, 11, 5, 3, 7, 8, 11, 9, 11, 8, 6, 4, 10, 8, 2, 6, 19, 3, 2,3, 28, 6, 1, 1, 1, 1, 0, 0), E = c(1.4, 8.7, 3, 2.5, 4.3, 2.4, 8.1,2.3, 2, 6.6, 4.4, 1.8, 1.1, 3.3, 7.8, 4.6, 1.1, 4.2, 5.5, 4.4,10.5, 22.7, 8.8, 5.6, 15.5, 12.5, 6, 9, 14.4, 10.2, 4.8, 2.9, 7,8.5, 12.3, 10.1, 12.7, 9.4, 7.2, 5.3, 18.8, 15.8, 4.3, 14.6, 50.7,8.2, 5.6, 9.3, 88.7, 19.6, 3.4, 3.6, 5.7, 7, 4.2, 1.8), X = c(16,16, 10, 24, 10, 24, 10, 7, 7, 16, 7, 16, 10, 24, 7, 16, 10, 7, 7,10, 7, 16, 10, 7, 1, 1, 7, 7, 10, 10, 7, 24, 10, 7, 7, 0, 10, 1,16, 0, 1, 16, 16, 0, 1, 7, 1, 1, 0, 1, 1, 0, 1, 1, 16, 10), num =c(3, 2, 1, 3, 3, 0, 5, 0, 5, 4, 0, 2, 3, 3, 2, 6, 6, 6, 5, 3, 3, 2,4, 8, 3, 3, 4, 4, 11, 6, 7, 3, 4, 9, 4, 2, 4, 6, 3, 4, 5, 5, 4, 5,4, 6, 6, 4, 9, 2, 4, 4, 4, 5, 6, 5), adj = c(19, 9, 5, 10, 7, 12,28, 20, 18, 19, 12, 1, 17, 16, 13, 10, 2, 29, 23, 19, 17, 1, 22,16, 7, 2, 5, 3, 19, 17, 7, 35, 32, 31, 29, 25, 29, 22, 21, 17, 10,7, 29, 19, 16, 13, 9, 7, 56, 55, 33, 28, 20, 4, 17, 13, 9, 5, 1,56, 18, 4, 50, 29, 16, 16, 10, 39, 34, 29, 9, 56, 55, 48, 47, 44,31, 30, 27, 29, 26, 15, 43, 29, 25, 56, 32, 31, 24, 45, 33, 18, 4,50, 43, 34, 26, 25, 23, 21, 17, 16, 15, 9, 55, 45, 44, 42, 38, 24,47, 46, 35, 32, 27, 24, 14, 31, 27, 14, 55, 45, 28, 18, 54, 52, 51,43, 42, 40, 39, 29, 23, 46, 37, 31, 14, 41, 37, 46, 41, 36, 35, 54,51, 49, 44, 42, 30, 40, 34, 23, 52, 49, 39, 34, 53, 49, 46, 37, 36,51, 43, 38, 34, 30, 42, 34, 29, 26, 49, 48, 38, 30, 24, 55, 33, 30,28, 53, 47, 41, 37, 35, 31, 53, 49, 48, 46, 31, 24, 49, 47, 44, 24,54, 53, 52, 48, 47, 44, 41, 40, 38, 29, 21, 54, 42, 38, 34, 54, 49,40, 34, 49, 47, 46, 41, 52, 51, 49, 38, 34, 56, 45, 33, 30, 24, 18,55, 27, 24, 20, 18), sumNumNeigh = 234)#INITIAL VALUESlist(tau = 1,alpha0 = 0, alpha1 = 0, b = c(0, 0, 0, 0, 0, NA, 0, NA, 0, 0, NA,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0))
WinBUGS在统计分析中的应用第一部分完
齐韬. WinBUGS在统计分析中的应用(第一部分). 统计之都,2008.12. URL: http://cos.name/2008/12/statistical-analysis-and-winbugs-part-1/.
在这一节中,我将拿一个经典的研究数据,利用WinBUGS给出简单的分析。首先介绍一下这个数据:Seeds
seed O. aegyptiaco 75 seed O. aegyptiaco 73 Bean Cucumber Bean Cucumber r n r/n r n r/n r n r/n r n r/n 10 39 0.26 5 6 0.83 8 16 0.5 3 12 0.25 23 62 0.37 53 74 0.72 10 30 0.33 22 41 0.54 23 81 0.28 55 72 0.76 8 28 0.29 15 30 0.5 26 51 0.51 32 51 0.63 23 45 0.51 32 51 0.63 17 39 0.44 46 79 0.58 0 4 0 3 7 0.43 10 13 0.77
这个数据来自Crowder(1978)。之后Breslow and Clayton (1993)作为例子,也分析过这个数据。数据反映的是某一品种的豆类种子和某一品种的黄瓜种子,分别放在21个培养皿(plates)中分别培养,在根提取物aegyptiaco75和aegyptiaco 73的作用下的出芽率的差异。其中r是出芽的个数,n是种子的个数,而r/n是出芽率。我们用randomeffect logisticregression模型来进行分析(注意,在Bayesian分析中,通常是将covariates看做是服从某一个分布的随机变量,这和一般意义上的GLM,GLME, LME中对于covariates解释是不同的):
其中是种子的类型,是根提取物的类型,是交互项, 是给定的独立的 “noninformative”先验参数。在Bayesian分析中,通常我们会定义一个DAG图(即Directed Acyclic Graph有向无圈图)。我们可以在WinBUGS中通过设计DAG图来定义模型。不过这一节中我们还是用WinBUGS中的BUGS语言来定义模型,如何在WinBUGS中通过设计DAG图来定义模型我将在下一节中详细介绍,但是必须要说明的是BUGS语言比DAG图灵活,不过直观性不如后者。
模型
model { for( i in 1 : N ) { r[i] ~ dbin(p[i],n[i]) b[i] ~ dnorm(0.0,tau) logit(p[i]) <- alpha0 + alpha1 * x1[i] + alpha2 * x2[i] + alpha12 * x1[i] * x2[i] + b[i] } alpha0 ~ dnorm(0.0,1.0E-6) alpha1 ~ dnorm(0.0,1.0E-6) alpha2 ~ dnorm(0.0,1.0E-6) alpha12 ~ dnorm(0.0,1.0E-6) tau ~ dgamma(0.001,0.001) sigma <- 1 / sqrt(tau) } 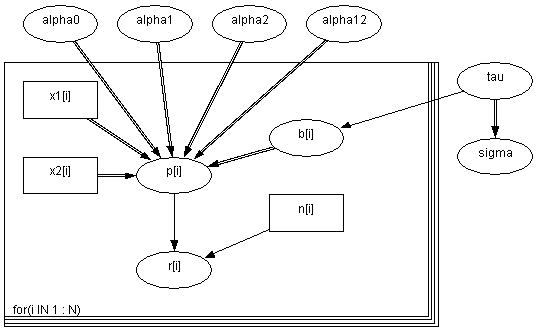
WinBUGSdoodle模型
数据
list(r = c(10, 23, 23, 26, 17, 5, 53, 55, 32, 46, 10, 8, 10, 8, 23, 0, 3, 22, 15, 32, 3), n = c(39, 62, 81, 51, 39, 6, 74, 72, 51, 79, 13, 16, 30, 28, 45, 4, 12, 41, 30, 51, 7), x1 = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1), x2 = c(0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1), N = 21)
初始值
list(alpha0 = 0, alpha1 = 0, alpha2 = 0, alpha12 = 0, tau = 1)
经过10000次迭代,我们得到参数的估计如下:
node mean sd MC error 2.50% median 97.50% start alpha0 -0.5546 0.1941 0.007696 -0.9353 -0.5577 -0.1597 1001 alpha1 0.08497 0.3127 0.01283 -0.5814 0.09742 0.6679 1001 alpha12 -0.8229 0.4321 0.01785 -1.697 -0.8218 0.01641 1001 alpha2 1.356 0.2743 0.01236 0.8257 1.347 1.909 1001 sigma 0.2731 0.1437 0.007956 0.04133 0.2654 0.5862 1001
下面我们用同样的数据在SAS中进行分析,看看结果相差多少:
首先生成数据:
data seeds; input plate r n seed extract; datalines; 1 10 39 0 0 2 23 62 0 0 3 23 81 0 0 4 26 51 0 0 5 17 39 0 0 6 5 6 0 1 7 53 74 0 1 8 55 72 0 1 9 32 51 0 1 10 46 79 0 1 11 10 13 0 1 12 8 16 1 0 13 10 30 1 0 14 8 28 1 0 15 23 45 1 0 16 0 4 1 0 17 3 12 1 1 18 22 41 1 1 19 15 30 1 1 20 32 51 1 1 21 3 7 1 1 ; run; da ta seeds; set seeds; interact=seed*extract; run; proc print; run;
然后调用GENMOD过程,拟合经典的logisticregression回归模型
proc genmod data=seeds; title ‘Classical logistic regression’; model r/n= seed extract interact / dist=B; run;
得到
Analysis Of Parameter Estimates Parameter DF Estimate Standard Error Wald 95% Confidence Limits Chi-Square Pr > ChiSq Intercept 1 -0.5582 0.126 -0.8052 -0.3112 19.62 <.0001 seed 1 0.1459 0.2232 -0.2915 0.5833 0.43 0.5132 extract 1 1.3182 0.1775 0.9704 1.666 55.17 <.0001 interact 1 -0.7781 0.3064 -1.3787 -0.1775 6.45 0.0111 Scale 0 1 0 1 1
调用NLMIXED过程,拟合经典的logisticregression回归模型
proc nlmixed data=seeds; title 'Classical logistic regression with NLMIXED'; parms b0=-0.55 b1=0.15 b2=1.32 b12=-0.78; logitp=b0+b1*seed+b2*extract+b12*interact; p=exp(logitp)/(1+exp(logitp)); model r ~ binomial(n,p) ; run;
得到:
Parameter Estimates Parameter Estimate Standard Error DF t Value Pr > |t| Alpha Lower Upper Gradient b0 -0.5582 0.126 21 -4.43 0.0002 0.05 -0.8202 -0.2961 -0.00000229 b1 0.1459 0.2232 21 0.65 0.5203 0.05 -0.3182 0.61 -8.82E-07 b2 1.3182 0.1775 21 7.43 <.0001 0.05 0.9491 1.6872 -0.00000161 b12 -0.7781 0.3064 21 -2.54 0.0191 0.05 -1.4154 -0.1408 -6.61E-07
调用NLMIXED过程,拟合经典带随机截距的logisticregression回归模型
proc nlmixed data=seeds; title 'Logistic regression with random plate intercept (NLMIXED)'; parms b0=-0.55 b1=0.15 b2=1.32 b12=-0.78; logitp=b0+b1*seed+b2*extract+b12*interact+alpha; p=exp(logitp)/(1+exp(logitp)); random alpha ~ normal(0,varu) subject=plate out=seedmixed; model r ~ binomial(n,p) ; run;
得到:
Parameter Estimates Parameter Estimate Standard Error DF t Value Pr > |t| Alpha Lower Upper Gradient b0 -0.5484 0.1666 20 -3.29 0.0036 0.05 -0.896 -0.2009 -0.00087 b1 0.097 0.278 20 0.35 0.7308 0.05 -0.483 0.677 0.00022 b2 1.337 0.2369 20 5.64 <.0001 0.05 0.8428 1.8313 -0.00018 b12 -0.8104 0.3852 20 -2.1 0.0482 0.05 -1.6139 -0.007 0.00037 1.07 0.295 varu 0.05581 0.05 20 9 0.05 -0.0527 0.1643 0.001515
当然了winBUGS的强大之处并不在于此,而是在处理诸如GLME(有些文献称GLMM),空间数据模型等计算复杂的模型,之后还会继续讨论。
参考文献:
[1]Crowder M J (1978) Beta-binomial Anova for proportions. AppliedStatistics. 27, 34-37.
[2]
最后再送出一本书,供大家研究参考
Disease Mapping with WINBUGS andMLWin(djvu格式)
WinBUGS在统计分析中的应用第二部分完
齐韬. WinBUGS在统计分析中的应用(第二部分). 统计之都,2008.12. URL: http://cos.name/2008/12/statistical-analysis-and-winbugs-part-2/.
GeoBUGS是WinBUGS的一个模块,专门用来分析空间数据(spatialda
下面是一个简单的例子,大家也可以在GeoBUGS的Manual中找到它。模型假设为条件自回归模型ConditionalAutoregressive(CAR)。数据为苏格兰唇癌疾病数据,反映的是苏格兰56个郡的唇癌发病率。这个数据比较经典,Claytonand Kaldor (1987) 和 Breslow and Clayton(1993)都曾在他们的论著中分析过该数据。
County Observed Expected Percentage SMR Adjacent cases (Oi) cases (Ei) in agric.(xi) counties 1 9 1.4 16 652.2 5,9,11,19 2 39 8.7 16 450.3 7,10 … … … … … … 56 0 1.8 10 0.0 18,24,30,33,45,55
County为郡的编号。
Observedcases(记作:Oi)为实际患病人数。
Expectedcases(记作:Ei)为预计患病人数,这个人数基于当地的人口,对象的年龄、性别分布。
Percentage inagric.(记作:xi)为当地农业、渔业、林业人口所占当地总人口的比例。
Adjacent counties指的是与当前郡相毗邻的郡的编号。
SMR(StandardisedMortality Ratios)为标准死亡率。
通过观察数据,我们可以发现SMR在某些时候(比如Oi和Ei较小时)出现奇异的值(如0.0),所以我们需要通过smooth方法来调整SMR的值。这里我们采用的方法是在条件自相关(CAR)的先验假定下,拟合具有空间相关的随机混效Poisson模型。模型如下:

其中为intercept项反映的是各个区域间患病的相对基准风险。
反映的是与地域相关的潜在的患病风险因子。其他项不言自明。
需要重点提出的是这里的,在GeoBUGS中可以通过car.normal先验分布来描述。在贝叶斯统计中任河变量都可以通过一个分布来描述。
b[1:N] ~ car.normal(adj[], weights[], num[], tau)
adj[]为邻接郡的编号
weights[]为描述各个郡之间重要性差异的权因子
num[]每个郡的相邻郡的个数
tau反映的是精度,因为不知道,所以在模型设定时要将其放到先验参数中去。
通过前两次介绍的方法,我们很容易就可以得到模型的结果。下面我们来看看如何将结果反映到地图上去。

GeoBUGS的地图工具配置界面
第一步,打开Map->Map Tool菜单,选择Scotland这张地图
第二步,在variable中填O或者E或者b等等模型参数
第三步,设置分割点和地图模板
第四步,点击plot画图
当然还可以在quantity中设置不同的需要反映的量的类型。
很简单吧。

GeoBUGS生成的地图
GeoBUGS还提供了一些小工具,比如AdjacencyMap来查看邻接图。

用GeoBUGS显示邻接地图
以下是WinBUGS用到的模型代码:
#Model model { for (i in 1:N) { O[i] ~ dpois(mu[i]) log(mu[i]) <- log(E[i]) + alpha0 + alpha1 * X[i]/10 + b[i] RR[i] <- exp(alpha0 + alpha1 * X[i]/10 + b[i]) # Area-specific relative risk (for maps) } # CAR prior distribution for random effects: b[1:N] ~ car.normal(adj[], weights[], num[], tau) for (k in 1:sumNumNeigh) { weights[k] <- 1 } # Other priors: alpha0 ~ dflat() alpha1 ~ dnorm(0, 1e-05) tau ~ dgamma(0.5, 5e-04) # prior on precision sigma <- sqrt(1/tau) # standard deviation } #Data list(N = 56, O = c(9, 39, 11, 9, 15, 8, 26, 7, 6, 20, 13, 5, 3, 8, 17, 9, 2, 7, 9, 7, 16, 31, 11, 7, 19, 15, 7, 10, 16, 11, 5, 3, 7, 8, 11, 9, 11, 8, 6, 4, 10, 8, 2, 6, 19, 3, 2, 3, 28, 6, 1, 1, 1, 1, 0, 0), E = c(1.4, 8.7, 3, 2.5, 4.3, 2.4, 8.1, 2.3, 2, 6.6, 4.4, 1.8, 1.1, 3.3, 7.8, 4.6, 1.1, 4.2, 5.5, 4.4, 10.5, 22.7, 8.8, 5.6, 15.5, 12.5, 6, 9, 14.4, 10.2, 4.8, 2.9, 7, 8.5, 12.3, 10.1, 12.7, 9.4, 7.2, 5.3, 18.8, 15.8, 4.3, 14.6, 50.7, 8.2, 5.6, 9.3, 88.7, 19.6, 3.4, 3.6, 5.7, 7, 4.2, 1.8), X = c(16, 16, 10, 24, 10, 24, 10, 7, 7, 16, 7, 16, 10, 24, 7, 16, 10, 7, 7, 10, 7, 16, 10, 7, 1, 1, 7, 7, 10, 10, 7, 24, 10, 7, 7, 0, 10, 1, 16, 0, 1, 16, 16, 0, 1, 7, 1, 1, 0, 1, 1, 0, 1, 1, 16, 10), num = c(3, 2, 1, 3, 3, 0, 5, 0, 5, 4, 0, 2, 3, 3, 2, 6, 6, 6, 5, 3, 3, 2, 4, 8, 3, 3, 4, 4, 11, 6, 7, 3, 4, 9, 4, 2, 4, 6, 3, 4, 5, 5, 4, 5, 4, 6, 6, 4, 9, 2, 4, 4, 4, 5, 6, 5), adj = c(19, 9, 5, 10, 7, 12, 28, 20, 18, 19, 12, 1, 17, 16, 13, 10, 2, 29, 23, 19, 17, 1, 22, 16, 7, 2, 5, 3, 19, 17, 7, 35, 32, 31, 29, 25, 29, 22, 21, 17, 10, 7, 29, 19, 16, 13, 9, 7, 56, 55, 33, 28, 20, 4, 17, 13, 9, 5, 1, 56, 18, 4, 50, 29, 16, 16, 10, 39, 34, 29, 9, 56, 55, 48, 47, 44, 31, 30, 27, 29, 26, 15, 43, 29, 25, 56, 32, 31, 24, 45, 33, 18, 4, 50, 43, 34, 26, 25, 23, 21, 17, 16, 15, 9, 55, 45, 44, 42, 38, 24, 47, 46, 35, 32, 27, 24, 14, 31, 27, 14, 55, 45, 28, 18, 54, 52, 51, 43, 42, 40, 39, 29, 23, 46, 37, 31, 14, 41, 37, 46, 41, 36, 35, 54, 51, 49, 44, 42, 30, 40, 34, 23, 52, 49, 39, 34, 53, 49, 46, 37, 36, 51, 43, 38, 34, 30, 42, 34, 29, 26, 49, 48, 38, 30, 24, 55, 33, 30, 28, 53, 47, 41, 37, 35, 31, 53, 49, 48, 46, 31, 24, 49, 47, 44, 24, 54, 53, 52, 48, 47, 44, 41, 40, 38, 29, 21, 54, 42, 38, 34, 54, 49, 40, 34, 49, 47, 46, 41, 52, 51, 49, 38, 34, 56, 45, 33, 30, 24, 18, 55, 27, 24, 20, 18), sumNumNeigh = 234) #Inits list(tau = 1, alpha0 = 0, alpha1 = 0, b = c(0, 0, 0, 0, 0, NA, 0, NA, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)) WinBUGS在统计分析中的应用第三部分完
齐韬. WinBUGS在统计分析中的应用(第三部分). 统计之都,2009.02. URL: http://cos.name/2009/02/statistical-analysis-and-winbugs-part-3/.
之前有些对GeoBUGS感兴趣的同学发邮件询问我有没有GeoBUGS的中国地图,以用于分析中国国内的一些空间数据。我想有必要将如何生成GeoBUGS格式的地图的方法分享给大家。这样的话,GeoBUGS就可以真正为我们所用,从而对于其他GeoBUGS没有自带的地图,我们也可以轻松生成了。本节不涉及统计分析,仅为GeoBUGS的研究使用者提供一个软件使用的技术参考。关于GeoBUGS的统计的书,国外实在是很多了,但关于这块地图定制的参考资料较少,故提出来供大家参阅。
目前分析用地图普遍采用的是shp格式,该格式可以用ESRI公司开发的ArcInfo工具进行编辑和分析。由于其通用性,故很容易在网上找到相应的资源。比如可以在国家基础地理信息系统的网站(http://nfgis.nsdi.gov.cn/nfgis/chinese/)上下载到有用的shp文件。我们主要需要的是其中的国界和省界的shp文件。可以点击链接下载中国省级行政区域地图shp版。我们要用到的是其中的bou2_4p.shp文件。
第一步,打开ArcInfo,选中Layers(图层),点击右键,在打开的菜单中选择AddDa
第二步,打开位于图层工具箱上方的Editor按钮菜单,在其中选中Start Editing。
第三步,选中bou2_4p图层,右键选中Open Attribute Table,
你会发现这个地图的精度过高,如浙江省的舟山群岛,多边形区域数目很多,而在一般的GeoBUGS分析中,这些多边形区域可以不予显示。所以我们可以通过删减,得到只含有主要部分的中国行政区域地图。一个简便的方法是对区域面积进行排序,小于一定阈值的区域予以删除。例如可以以Area=.066的香港特别行政区为界,删除所以面积小于0.066的区域。
第四步,打开位于图层工具箱上方的Editor按钮菜单,在其中选中Stop Editing,并保存你的修改。
第五步,在ArcToolBox中选择Conversion Tools
将InputFeature classes定位到修改后的bou2_4p.shp。在XYTolerance(optional)中设定精度,这里我将其设定为0.005 Decimaldegrees。其他参数取默认值。
第六步,在ArcToolBox中选择Coverage Tools
第七步,编辑GeoBUGS支持的格式,在bou2_4p_feat1.txt中添加一段头,如下
map:33 1 Heilongjiang 2 NeiMonggol 3 Xingjiang 4 Jilin 5 Liaoning 6 Gansu 7 Hebei 8 Beijing 9 Shanxi 10 Tianjin 11 Shaanxi 12 Ningxia 13 Qinghai 14 Shandong 15 Xizang 16 Henan 17 Jiangsu 18 Anhui 19 Sichuan 20 Hubei 21 Chongqing 22 Shanghai 23 Zhejiang 24 Hunan 25 Jiangxi 26 Yunnan 27 Guizhou 28 Fujian 29 Guangxi 30 Taiwan 31 Hainan 32 Guangdong 33 Hongkong regions 1 Heilongjiang 2 NeiMonggol 3 Xingjiang 4 Jilin 5 Liaoning 6 Gansu 7 Hebei 8 Beijing 9 Shanxi 10 Tianjin 11 Hebei 12 Shaanxi 13 Ningxia 14 Qinghai 15 Shandong 16 Xizang 17 Henan 18 Jiangsu 19 Anhui 20 Sichuan 21 Hubei 22 Chongqing 23 Shanghai 24 Shanghai 25 Zhejiang 26 Hunan 27 Jiangxi 28 Yunnan 29 Guizhou 30 Fujian 31 Guangxi 32 Taiwan 33 Hainan 34 Guangdong 35 Hongkong END
map:33表示这个中国地图有33个行政区域,而regions:35表示后面给出的通过经纬坐标描述的多边形区域隶属于那个行政区域。
第八步,在GeoBUGS中打开这个txt文件,然后选择Map -> Imp
第九步,保存成GeoBUGS的.map文件
第十步,重启GeoBUGS,恭喜你可以在GeoBUGS中使用中国地图进行分析了。
生成的地图可以在这里下载中国行政区域地图GeoBUGS版。我们可以在许多政府官网得到许多可以分析的数据资源,如http://www.moh.gov.cn/publicfiles//business/htmlfiles/zwgkzt/pwstj/index.htm
那么就下载一些数据用GeoBUGS进行分析吧
WinBUGS在统计分析中的应用第四部分完
齐韬.WinBUGS在统计分析中的应用(第四部分). 统计之都, 2009.06. URL: http://cos.name/2009/06/statistical-analysis-and-winbugs-part-4/.
WinBugs1.3简易使用说明
Bugs网站:www.mrc-bsu.cam.ac.uk/bugs
1. 点选 图示,进入WinBugs,开启(1)新的程式编辑视窗or (2)已存在的程式功能表列:File-New 功能表列:File-Open
2.撰写程式:程式包含三部份.
(1)Model:建构贝氏统计模式,设定各参数的prior distribution及各参数间的关系等.
(2)Data:以list指令起始,列出各参数的样本观察值及样本个数(N= ).
(3) Initialvalue:同样运用list指令,列出各参数的起始值.
ps:上述三大部份的程式撰写顺序并不会影响程式执行结果
例:Seeds: randomeffects logistic regression (下图为WinBugsExamples中Seeds的例子)
Model:
ri ~ Binomial(pi,ni)
logit(pi) = α0 +α1x1i + α2x2i + α12x1ix2i + bi
bi ~ Normal(0,τ)
在功能表列选取File → Save as即可将程式储存於指定的档案夹内
这是状态列
Initialvalue
Data
Bayesianmodel
Priordistribution的设定
3. 执行程式
Step 1 在功能表列中点选:Model→ Specification,开启Specification Tool 视窗
Step 2 Checkmodel:
选取Model程式中的关键字"model",按下Specification Tool视窗的check model
键,若此部份程式的语法及定义无误,则:
(1) SpecificationTool 视窗的 compile 及 load data 键将会浮现,即可供执行
点选;
(2)WinBugs左下角的状态列将会显示'model is syntactically correct'
Step 3 Loaddata:
选取Data程式中的关键字" list",按下Specification Tool视窗的 load data 键
若资料型式无误,则WinBugs左下角的状态列将会显示'data loaded '
可选择一次simulate数个chains
Step 4 CompileModel:
直接按下SpecificationTool视窗的 compile 键,若程式无误,则WinBugs左
下角的状态列将会显示' modelcompiled '
Step 5 Load initialvalues:
选取Initialvalue程式中的关键字" list ",按下 load inits 键,若WinBugs
左下角的状态列显示:
(1) ' initial valuesloaded: model initialized ' 表示资料型式无误,接续Step6.
(2) ' initial valuesloaded: model contains uninitialized nodes ' 若程式没有缺
漏,会出现这样的讯息,则有两种可能:
(Ⅰ)当只simulate一个chain时,出现上述的讯息表示程式中尚有一些参数
还未定义起始值,会发生这样的状况,有时是因为未提供起始值之参数
(如Seeds例子中的:sigma)与其他参数间 (如:tau) 具有函数对应关
系,(如:sigma<- 1 / sqrt(tau));在此情况下,须再按下 gen inits 键,
让WinBugs依参数间的对应关系,自动为剩馀未定义起始值的参数生
成一个起始值,执行後,WinBugs左下角的状态列将会显示'initial
values generated:model initialized '.
(Ⅱ) 当simulate两个以上的chains时,这个讯息代表至少有一个chains 的
参数尚未定义起始值;同样地,亦可按下gen inits 键,自动生成起
始值,或者回到程式,自行定义起始值.
Step 6关闭Specification Tool视窗
4. Monitor感兴趣的参数
Step 1在功能表列中点选:Inference → Samples,开启Sample Monitor Tool 视窗
Step 2在node方块中输入想要monitor的参数,如:在Seeds范例中,欲generate posterior
samples的参数为:alpha0,alpha1,alpha2,alpha12,tau,sigma,此步骤便是
在node方块中输入这些参数名称,每输入一个参数名称,便按一次set 键,
待完全键入後,关闭此视窗.
ps:由於此步骤之作用仅在monitor参数,视窗中之beg,end,thin或chains皆
不会有任何作用,亦即更改其中的数值皆不会对output有任何影响,在此先
省略不谈,之後在simulatedvalue时将会对这些指令之功用提出简略的说明.
……
5. Update theModel
Step 1 在功能表列中点选:Model→ Update,开启Update Tool 视窗
Step 2在update方块中键入想要generate posterior samples的样本数,如:3000笔,按
下 update键,则iteration将由0 run 至3000,WinBugs左下角的状态列将会
显示generate posteriorsamples所需的时间,如:' updates took 1 s ',执行完後
关闭Update Tool 视窗.refresh=100 表示在iteration方块中,将会以100为单位,显示正在update
的进度,refresh值愈小,将愈加重其显示的量,则update速度会变慢.
若thin方块中之数值改为5,表示每隔5笔收一笔资料,共收3000笔,以整
个Markovchain来看,WinBugs会保留的样本是第5, 10, 15,…, 15000笔资料
6. 显示simulated values(posterior samples)
Step 1在功能表列中点选:Inference → Samples,开启Sample Monitor Tool 视窗
Step 2 Sample MonitorTool视窗内各个选项的执行程序与作用:
(1)由於之前曾在此视窗中monitor各个参数,因而现在若欲同时显现所有
monitor 参数的结果,则可在node方块中键入'*',以代表全体参数;
若仅需部分参数的posteriorsamples及其统计推论结果,则在node方块中输
入该参数名即可.
(2) Burnin:为降低起始值的影响,选取递回後较稳定的资料,因此在分析时
常常需要Burn in前面较不稳定的资料.假设现欲Burn in 前一
千笔资料,则需在beg
http://wenku.baidu.com/view/4a5e5c4ac850ad02de8041fa
Jacobiterm
贝叶斯-蒙特卡罗
spatial heterogeneitymodels
spatial heterogeneityspatial dependence
听徐雷教授关于贝叶斯阴阳和谐统计学习理论
预测性伪似然法和贝叶斯法广义线性混合模型估计
【作 者】曹红艳 刘桂芬 曾平 张爱莲
【机 构】山西医科大学公共卫生学院,太原030001
【刊 名】《中国药物与临床》 2008年第8卷第11期,861-863页
【关键词】线性模型 广义线性混合效应模型 贝叶斯 马尔可夫蒙特卡罗 预测性伪似然法
【文 摘】目的比较预测性伪似然法(PQL)和基于马尔可夫蒙特卡罗(MCMC)的贝叶斯方法在广义线性混合模型参数估计的偏差和精度。方法针对样本含量不等的层次数据,运用SAS/glimmix过程和WinBUGS软件分别进行PQL和贝叶斯法参数估计。结果两种方法固定效应参数估计结果基本一致,但对随机效应方差的估计,基于MCMC的贝叶斯法偏差远小于PQL法。结论对二分类层次数据,采用广义线性混合效应模型贝叶斯估计精度更高,偏差更小。
空间流行病学研究中的贝叶斯统计方法
贝叶斯统计学通过构建分层贝叶斯模型,结合马尔科夫链-蒙特卡罗方法,可以有效地对包括小范围区域疾病分布图的描绘、疾病地理聚集性分析研究和疾病地理相关性研究在内的时空非独立数据进行分析.目前贝叶斯空间分析模型已发展成多类的分析方法,包括近年来充分发展和得到应用的BYM模型、联合随机模型、半参数贝叶斯统计及移动性均化模型等.同时,通过离差信息准则,开展了众多的模型比较分析;其中,以BYM模型和半参数模型中的MIX模型的优势较明显.随着进一步的深入研究,贝叶斯统计学在空间流行病学研究中发挥的空间将进一步增大.作者:郑卫军
作者单位: 浙江大学医学院,流行病与卫生统计系,浙江,杭州,310058
期 刊: 浙江大学学报(医学版)
Journal: JOURNAL OF ZHEJIANG UNIVERSITY(MEDICALSCIENCES)
年,卷(期): 2008, 37(6)
联系客服

