
在学习 DQN 算法之前,先了解一下它所属的分类——强化学习。
将强化学习和之前所学的有监督学习做个对比:如果说有监督学习是通过标记来训练模型,强化学习则是通过奖励来训练模型。
在强化学习中,机器基于环境做出行为,正确的行为能够获得奖励。以获得更多奖励为目标,实现机器与环境的最优互动。
做个类比,教狗子握手的时候,如果狗子正确握手,就能得到骨头奖励,不握手就没有。倘若咬了主人一口,还会受到惩罚。长此以往,狗子为了得到更多骨头,就能学会握手这个技能。
看似很直白,但这就是强化学习的原理,只不过要把狗子换成电脑。
强化学习之下有很多算法,它们的原理都是相同的——通过奖励来训练模型。只是在实现方式和学习效率上各有不同。
理解了强化学习的原理后,再通过一个例子理解它和有监督学习的区别。
还记得围棋大师——AlphaGo 吗?
有监督学习就是给 AlphaGo 大量已经标记出最优解的棋谱,告诉它在每个场景下的最优落子位置,通过这种方式让 AlphaGo 学习围棋。
但是,棋局的走势千变万化,棋谱无法囊括所有情况。因此,强化学习试图从另一个角度去解决这个问题。
强化学习让 AlphaGo 不断和对手下棋,如果一步棋对局势有帮助,就给它奖励;反之没有奖励,甚至受到惩罚。通过寻求更多奖励,AlphaGo 就能掌握精湛的棋艺。
用图片总结并对比了一下两种方式的区别:

在强化学习的过程中,会涉及六个要素:机器、环境、状态、行为、奖励、评论家。它们的关系如下图所示:
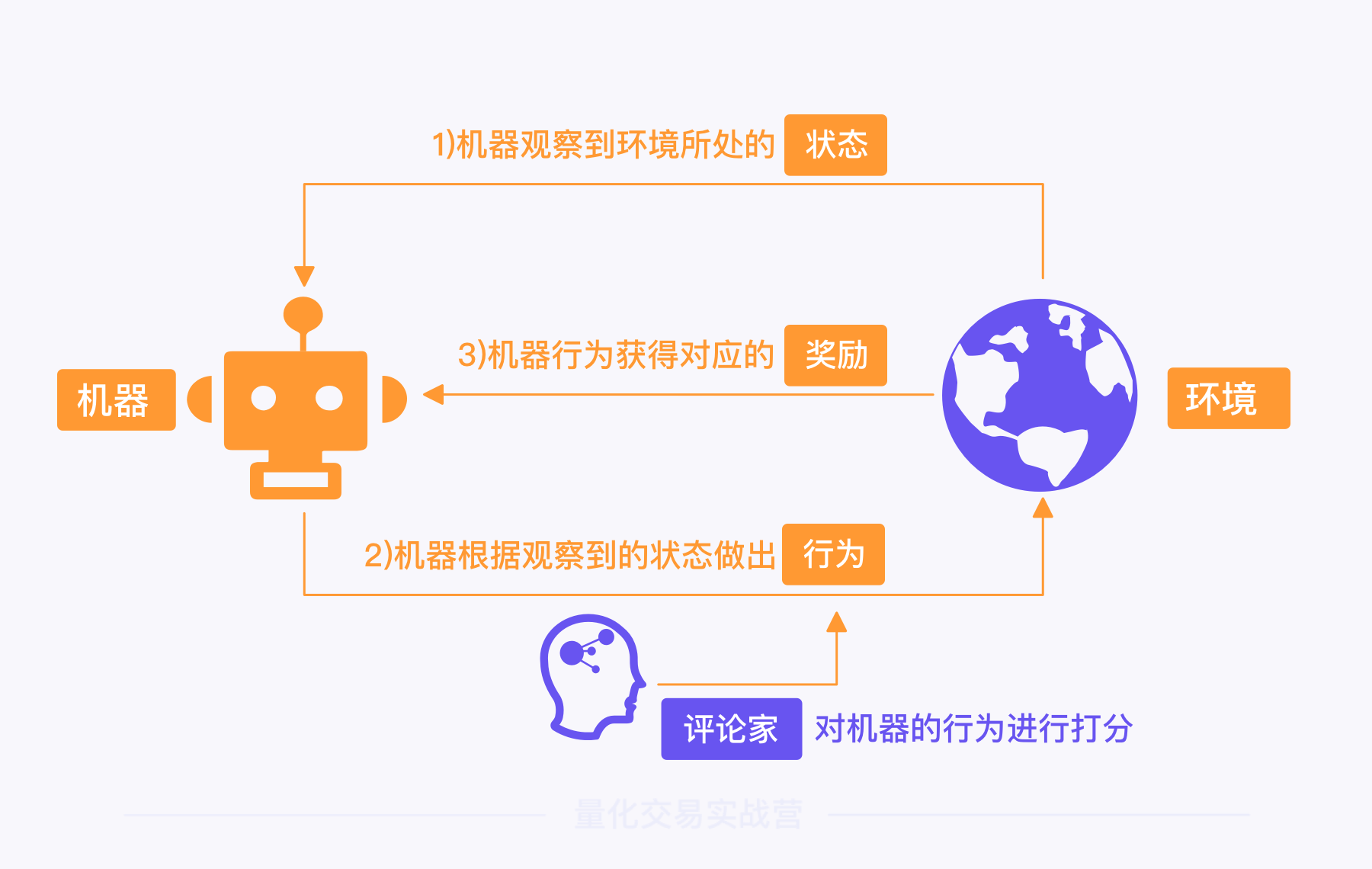
继续以 AlphaGo 为例,逐一讲解它们的含义。
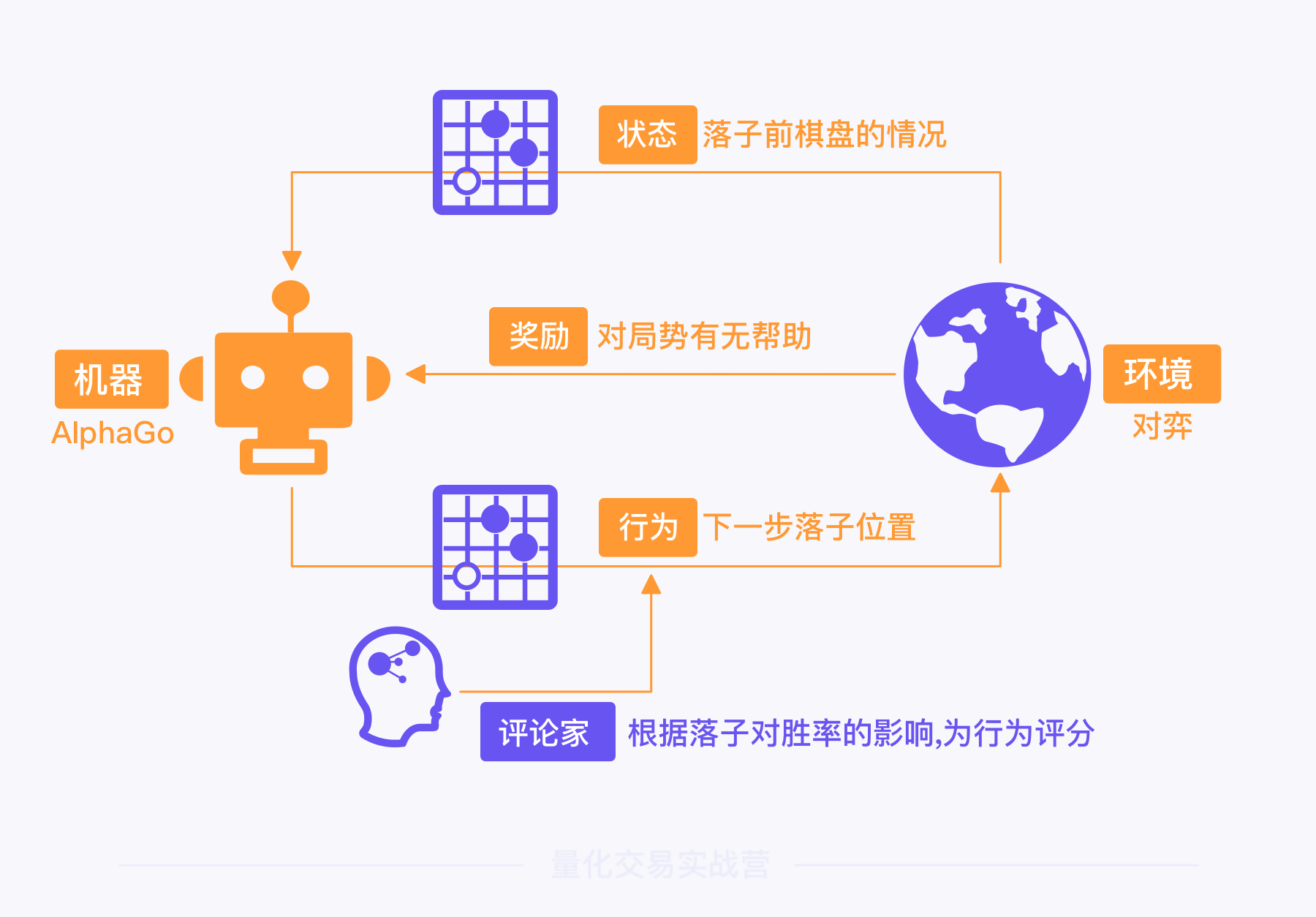
1)机器(Actor 或 Policy):是强化学习的训练对象,即决策模型,也就是 AlphaGo 。我们可以把它叫做机器或者策略,在算式中经常用 π 来表示。
2)环境(Environment):和机器发生互动的环境。在 AlphaGo 的例子中,环境就是对弈场景,包括对手、围棋规则等。
3)状态(State 或 Observation):环境当下所处的状态,可以理解为 AlphaGo 对弈时,每次落子前棋盘上的情况。
4)行为(Action):机器根据状态所做出的行为,也就是 AlphaGo 根据当前棋盘的情况,所选择的落子位置。机器做出行为后,会进入下一个状态,并根据新的状态再次做出行为,循环往复,直到互动结束。
5)奖励(Reward):机器的行为所获得的奖励。 对于 AlphaGo 来说,赢棋是一种正向奖励,输棋则是一种负面奖励。
6)评论家(Critic):一套行为评价体系,根据每个行为的价值进行打分。
在一盘棋局中,赢棋是好,输棋是坏,可是中间某一步棋的好坏很难评估,因此很难得到实时的奖励。这时就需要评论家,它可以计算出一步棋对整盘棋的价值,为每一步棋打分,给出实时的奖励。
用 AlphaGo 的例子,将这六个要素的关系串联起来。
在对弈的环境中,AlphaGo 根据棋盘上的状态,做出落子行为,然后每盘棋的胜负获得奖励。模拟足够多棋局后,评论家就可以通过计算预测出每步棋对整盘棋的价值,为其打分。
通过不断训练,机器以赢更多局棋为目标,不断更新优化,成为一个围棋大师。
当机器面对一个状态时,可选的行为往往有很多。根据行为能否被全部列举,可以将强化学习的场景分为两类:离散场景和连续场景。
离散指行为的个数有限或可数。一般来说,在离散场景下,可以把所有行为列举出来。
下面,通过一个经典游戏——坦克大战,进一步理解离散的含义:
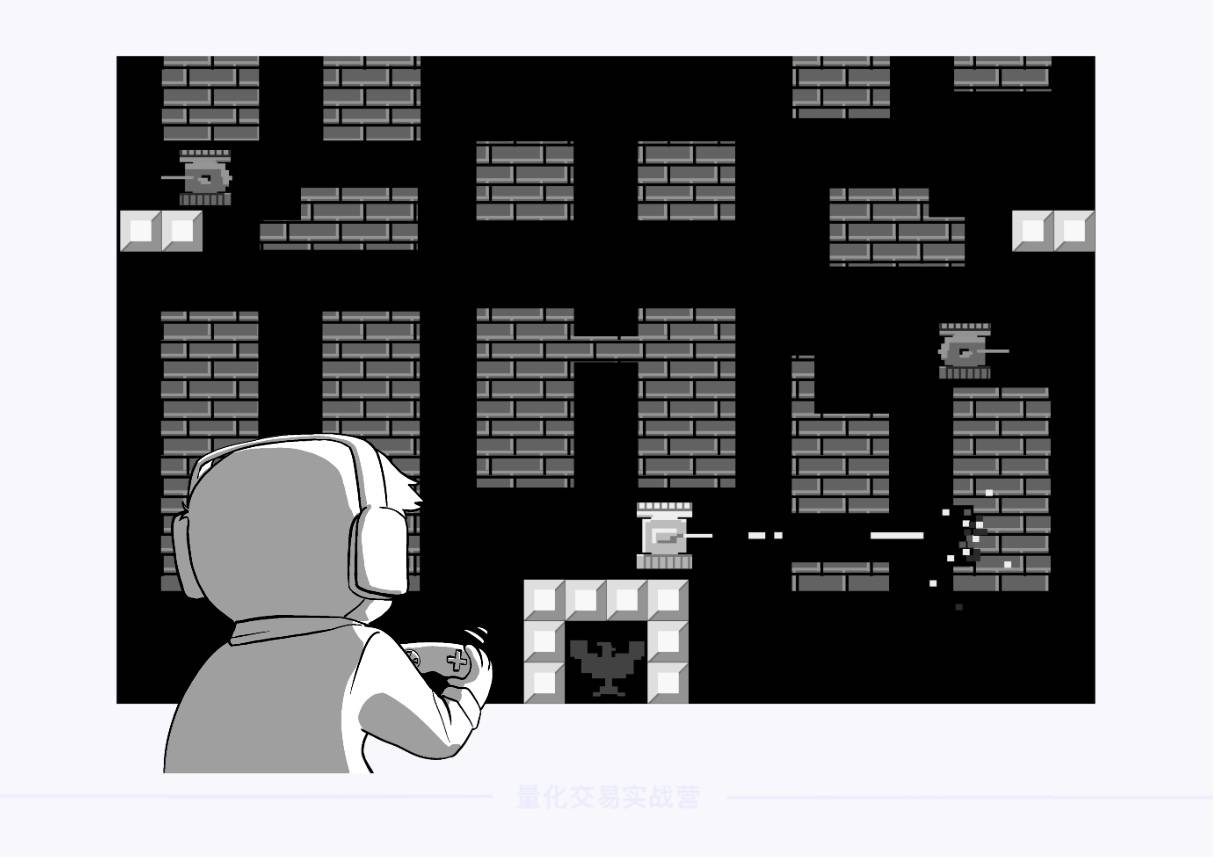
在坦克大战中,每个坦克可以做的行为是有限的、可数的,只有「向上、向下、向左、向右、开火」这五个动作,移动也只能一格一格地走。因此,如果你足够的时间和耐心,一场游戏中的情况可以被全部列举出来。
这种情况称为离散。
在离散场景下,数据搜集的难度并不高(对计算机来说)。假如要训练一个智能坦克,可以把每个状态下的所有行为列举出来,用评论家为每个行为打分,通过选择最高分的行为实现最优互动。
因为需要评估每个行为的价值(Value),所以这种强化学习方法被称为基于值(Value-Based)的方法,也可以被译作基于价值的方法。
在基于值的方法下,有一个经典算法,即本关学习的重点——DQN 算法。
连续指在一定区间内可以任意取值,相邻两个数值可以被无限分割。比如,从 0 到 1 之间,有 0.1、0.11、0.111、…
在强化学习的场景中,可以理解成机器的行为是连贯的。
比如模拟赛车的游戏,赛车的方向盘转动角度可以在一定区间内任意取值,角度之间可以无限分割。
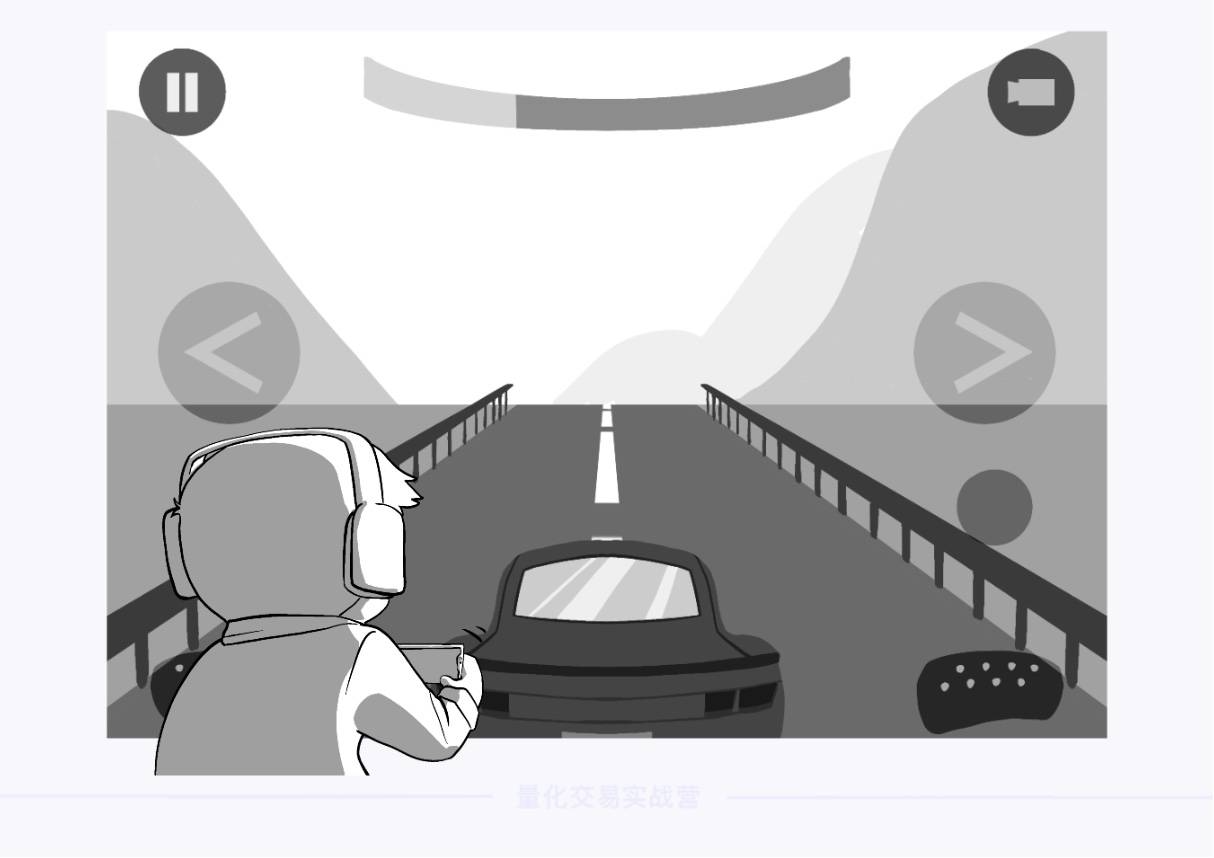
在这种背景下,即便是计算机也无法穷举出全部行为。因此,如果要训练一个智能驾驶员,基于值的方法就无法胜任。
这时需要用到另一种强化学习方法——基于策略(Policy-Based)的方法。它无需根据每个行为的价值来打分,可以很好地胜任连续场景。
DQN 算法全称 Deep Q Network,它以 Q-Learning 算法为基础,融合了神经网络(Neural Network),实现了更强大的强化学习功能。
Q-learning 也是一种基于值的强化学习算法,它在强化学习原理的基础上,引入了一个概念——Q 值。
Q 值表示做出一个行为后能够获得的累计奖励。它是算法模拟大量数据后,通过复杂的函数计算出来的。
并不需要深究具体计算过程,只需简单地把 Q 值理解成评论家(Critic),它的大小表示每个行为的价值。一个行为的 Q 值越高,表示该行为能带来的奖励越多,越应该被选择。
在训练 Q-learning 算法时,需要用到以下三类数据:
1) 环境的每一个状态,简称为 s(State);
2) 每个状态下所有行为,简称为 a(Action);
3) 每个行为的 Q 值,简称为 Q。
总结一下,Q-learning 算法需要知道每个状态(s)下,所有行为(a)的 Q 值。它的训练目标是,让机器在每个状态(s)下都能做出 Q 值最大的行为(a),从而实现机器与环境的最优交互。
Q-learning 训练时需要用到状态(s)和行为(a),以及它们所对应的 Q 值。它用表格来储存这三类数据,如下图所示:

可以这样理解这张图:在 状态 s1 下,行为 a1、a2、a3 的 Q 值分别是 1、0、2。因此 状态 s1下的最优行为就是 a3。
可是,当状态和行为的数量非常庞大时,用表格储存所有数据会占用非常多的资源。
比如下围棋,棋盘一共有 361 个点位,每个点位有“黑”、“白”、“空”三种情况,因此整个棋盘的布局有 3 的 361 次方个状态。用表格记录所有 s 和 a,这张表会无比巨大。
这是 Q-learning 面对复杂场景时的局限。
但是,在机器学习中,刚好有一个算法,擅长解决各种复杂问题,那就是 神经网络(Neural Network)。
下图是一张经典的神经网络原理图。最左边一列称为输入层,最右边一列为输出层,中间统称为隐藏层。神经网络的作用就是通过隐藏层来解释输入层与输出层的关系。
可以将输入层理解为高中数学函数里的 x,输出层理解为 y,隐藏层就是一长串函数表达式。
不过,神经网络可比高中的数学函数复杂太多,无需深究它的细节,可以简单地把它想象成一个模拟大脑。
例如,现在有大量的人脸照片,需要根据年龄段,判断照片上的人是儿童、青少年、青年、中年还是老年。
在这个场景中,所看到的照片就是输入层,判断结果就是输出层,大脑的判断过程就是隐藏层。
总结一下,神经网络就是通过算法来模拟大脑,解释数据之间(输入层、输出层)关系的算法。隐藏层越多,可以解释越复杂的数据。
既然 Q-learning 算法难以储存庞大的数据量,神经网络帮它解决这个问题
神经网络的隐藏层可以找到 s、a、Q 之间的关系。根据这个关系,只要向神经网络中输入 s,经过分析计算,就能输出对应的 a 和 Q 值。
这样一来,Q-Learning 就不再需要用巨大的表格储存数据,只需要知道状态(s),就能用神经网络自动生成其余数据。这大大节省了 Q-Learning 所需的资源。
再拿 AlphaGo 做个类比,神经网络的应用让 AlphaGo 无需记忆所有棋谱,而是在学习一些经典棋谱后,能够根据棋盘上的状态,自动推演出每一步棋的结果。
Q-Learning 算法和神经网络的融合,大大提高了机器的学习效率,这个融合的产物就是 DQN 算法。
DQN 算法是 Q-Learning 算法和神经网络算法的融合。Q-Learning 算法让机器能根据状态做出累计奖励更多的行为,而神经网络则提高了数据储存的效率。
其实,量化交易和前面所讲的下围棋、玩游戏并没有区别。可以将 DQN 模型放在投资环境中进行互动,训练出一个智能交易员。
其中:
1)机器所面对的状态(s)就是每个交易日的市场信息;
2)机器能做的行为(s)就是买入、卖出或持有;
3)行为的Q 值就是每次交易所能带来的累计收益。
因此,这个智能交易员的训练目标就是:根据每个交易日的市场信息(状态),决定买入、卖出或持有标的(行为),使得在退场前获得更多累计收益(Q 值)。
这其实就是量化交易中的择时。将每个交易日的市场信息传入 DQN 模型中,不断训练,就能成长为一个择时专家。
DQN 算法只能从买入、卖出和持有这三个行为中进行预测,但无法预测具体买卖多少。
原因很简单,DQN 算法属于基于值的方法,只能处理离散场景。
买入、卖出、持有,这是三个离散的行为。但涉及到具体仓位比例时,我可以买入 10% 的仓位,也可以买入 11%、11.1% 的仓位,这种行为是连续的。
所以,在使用 DQN 算法构建量化策略时,它只能给出交易的“方向”,具体交易多少则需要手动设置。
ForTrader 已经内嵌了 DQN 算法。
因此本环节要学的不是如何构建 DQN 算法,而是如何使用 DQN 算法来构建量化交易策略。
用 DQN 算法构建策略,可以简化成以下三个步骤。
第一步,在 DQN 算法开始训练前,进行一些基础设置。
第二步不需要做任何操作,ForTrader 内嵌的 DQN 算法会自动采集、处理数据并开始训练。训练完成后直接输出每个交易日的最优行为。
第三步,在进行交易决策时,不仅要考虑模型的预测结果,还要考虑账户的实际持仓情况。比如,即便 DQN 模型预测要卖出,但如果账户持仓不足,也无法进行交易。所以要进行额外的条件判断。
在指标模块,目的是为模型训练设置一些基础参数。
参数有点多,根据作用可以分成三类:数据范围相关参数、神经网络相关参数和交易相关参数。
通过 start_date、eval_date 和 end_date设置数据范围。
在 DQN 算法中,一次完整的训练,需要用到三个数据集:训练集、验证集和测试集。 这三个参数只和训练集与验证集有关:
其中,start_date 和 eval_date 之间是训练集;
eval_date 和 end_date 之间是验证集;
而测试集的范围就是在【条件设置】中设置的回测区间,无需用参数来设置。
在学习 SVM 算法时,接触了训练集和测试集的概念。在训练集中训练后的模型,可以直接放到测试集去检验效果(进行回测)。
但是,由于强化学习模型更加复杂,需要在训练集和测试集之间加一个中间步骤——验证集。
作用是,由于强化学习的过程非常复杂,在训练模型时会产生很多个版本,算法需要从多个版本中选出效果最好的一版。
这个选优的过程,就需要在验证集中完成。选出最优版本的模型后,再将它放到测试集中检验效果,即进行回测。
做个类比,可以将训练集理解为期末复习,测试集是期末考试。而验证集就是模拟考试,你可以在模拟考试中找到调整考试状态,找到最佳答题节奏。
为了让回测结果更可靠,回测区间(即测试集)不可以与训练集(start_date 至 eval_date)有重合。因为模型本身就是根据训练集数据训练出来的,倘若用训练集的数据回测,很容易得出好结果,无法准确反映模型的真实表现。
再提醒你一次,训练集、验证集的区间用参数设置,测试集则在【条件设置】中设置,不要混淆啦。
注意,这类参数涉及专业的神经网络知识,无需深究它们的算法含义,只需从量化策略的角度理解它们的用法即可。
1)hid_dim,表示神经网络隐藏层的维度。隐藏层的作用是寻找输入层与输出层之间的关系,隐藏层的维度越高,神经网络能处理的问题就越复杂。
基于经验,在 DQN 算法中将隐藏层维度设为 512(2 的 9 次方)是比较主流的做法。
2)learning_rate_q,表示神经网络的学习率。可以将强化学习的过程理解为机器一步一步向前更新的过程,学习率就表示向前的步长。
步长太大,尽管学得快,但会导致后期无法收敛于最优解;步长太小,则会导致学得很慢,学到黄花菜都凉了。
在打高尔夫球的时候,挥杆越用力,球前进的步长就越大,虽然能让球很快靠近洞口,但如果一直用力挥杆,球会一直在洞口附近反复横跳,很难进洞。
相反,挥杆越轻,球前进的步长越小,球要虽然要花更长时间靠近洞口,但到达洞口附近后更容易进洞。
基于经验,可以在 DQN 算法中将学习率设为 0.0001。
3)break_epoch,表示将全部数据送到模型中进行训练的轮数。
在高考复习时,想要取得好成绩,需要复习很多轮。第一轮先过一遍知识点,第二轮攻克重难点,第三轮刷重点题型、…。
训练模型也是同样的道理,break_epoch = 7 就是指将全部数据送入模型中训练 7 轮,并且每轮训练都有不同的侧重点。
4)repeat_times,表示每轮训练的重复次数。它和 break_epoch 比较类似,作用都是通过增加训练量让机器学得更好。
还是以高考复习作类比,帮你理解它们的区别。虽然已经将高考复习划分成很多轮,但在每一轮复习中,每个知识点还是要反复背诵很多遍。
repeat_times 就等价于每轮复习中,反复背诵知识点的次数。
在 DQN 算法中,repeat_times 的取值范围建议在 20 到 35 之间。
buy_on_percent 和 sell_on_percent 指的是买卖比例。
前面提到过,DQN 算法无法预测买卖的仓位比例,需要手动设置。
buy_on_percent = 1 表示每次买入时,都使用全部资金;若buy_on_percent = 0.5,则每次只用 50% 的资金买入。
卖出同理。sell_on_percent = 1 表示每次卖出时,都卖出全部持仓;若 sell_on_percent = 0.5,则每次卖出 50% 的持仓。
至此已经讲完了所有的参数。
还需要将这些参数传入给 DQN 算法。
DQN 算法的具体代码都被封装成了一个类,可以用 DQN()来调用它,然后将前面设置的参数一一对应地传入即可。
这些参数的取值可以影响训练效果。
参数有点多,用一张图总结了它们的含义,以及调参思路:
在讲解择时代码前,先回顾一下第三步:交易判断要做哪些事。
1)获取 DQN 算法的预测结果,以及当前的持仓规模;
2)根据二者的关系进行判断,下达交易指令。
通过 dqn.dqn_prediction[0] 就可以获取模型预测出的最优交易行为,以及订单数量,命名为 size。
如果 size > 0,代表买入一定仓位,size < 0代表卖出一定仓位,size = 0 表示不需要交易。
要注意的是,由于 DQN 模型无法预测连续的行为。因此这里的订单数量并不是模型预测的结果,而是根据指标模块所设置的参数 buy_on_percent 和 sell_on_percent 确定的。
为了满足 A 股市场的交易要求,因此需要将 size 转换成 100 的整数倍。可以通过 int(size / 100) * 100 的方式实现这一点。
获取当前交易日的持仓规模,命名为 position。
至此,已经获取了所需数据。
接下来就要结合数据进行判断,并下达交易指令了。
先通过一张图梳理一下判断逻辑:
如果算法预测买入,即 size > 0,则下达买入指令,买入数量为 size。
这一步对应择时逻辑图的最左边一列:
如果当前有持仓,且算法预测卖出。即 position > 0 且 size < 0 时,需要做进一步判断。
如果当前持仓规模大于预测卖出的数量,即 position > abs(size) 时,就按照预测的卖出数量卖出,即订单数量为 size。
注意,这一由于 size < 0,所以要用 abs() 函数取它的绝对值,再进行比较。
这一步的判断逻辑如下图所示:
如果当前持仓规模小于或等于预测卖出的数量,只好有多少卖多少,即执行平仓。
由于其他情况的结果都是不执行交易,因此可以省略。
策略总收益率为 1.54%,跑赢了买入并持有收益,勉强能接受。
指标模块代码:
择时模块代码:
在指标模块中,参数可以分成三类:数据范围相关参数、神经网络相关参数、交易相关参数。
在讲解这些参数含义的时候,已经讲过了它们的调参逻辑。先来回顾一下吧:
其中,数据范围相关参数的作用最容易理解,它们决定了训练和检验模型时所用的数据样本量。一般来说,样本量越大,有助于得出更好的结果。
而神经网络相关参数相对难懂一些。不过,正所谓“前人栽树,后人乘凉”,站在巨人的肩膀上学习才真香。
业界已经对 DQN 算法进行过大量研究。因此,不用漫无目的地调试参数,可以基于经验进行取值。
至于交易相关参数,可以明确 buy_on_percent和sell_on_percent 的取值范围都在 0 到 1 之间。建议以 0.1 作为步长,逐个尝试。
下面,就可以尝试在 ForTrader 中进行参数调优了。
通过扩大训练集的数据范围,可以扩大学习的样本数量,让模型学得更好。就好像考前复习时,刷过的题型越多,在正式考试中就越有把握。
不过,在选择训练集时,需要注意数据的有效性。由于市场环境的变化,过于久远的的交易数据可能对当下的投资不具备参考价值。
例如,2007 年 A 股市场发生过一次政策变化,如果囊括 2007 年以前的股票数据,放入模型中训练,就如同让学生按照已经过时的考纲准备考试,造成无效学习。
因此,不妨试试把训练集的起始时间提前到 2008-01-01。
将训练集扩大后,总收益率达到了 7.03%,收益相较原本的 1.54% 提升了很多。
提示:
本公司发布内容均为市场公开信息,不构成投资建议,投资者据此操作,风险自担。市场有风险,投资需谨慎!
联系客服

