(基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第二部分(连载)Posted on 2012-07-13 17:29
Bang 阅读(363) 评论(0)
编辑续
第一部分消息(Messages)
翻译源程序时,Parser需要汇报一些状态信息,比如发现语法错误后的错误消息。不过你不能让paser关心该在那儿发送消息或者消息收到之后该怎么处理。类似地,source(类)组件每读入一行时可发送一条包含行文本和行号的消息。接收者可能用这些消息产生一个源码清单,但是你不能让source组件操心这事。
设计笔记
保持消息的发送者(parser和source)与消息接收者之间松耦合。两个组件松耦合就是说他们之间的依赖最小,一个组件能够很容易在不对另一组件造成不利影响下更改。在大型复杂应用中,松耦合能让独立组件开发与团队并行组件开发和谐相处。
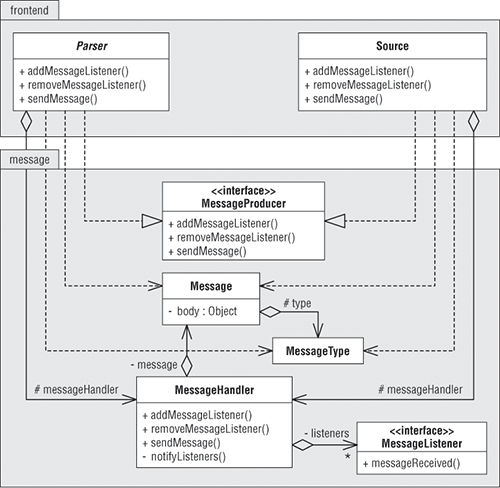
图2-4 针对图2-3 进行了扩展,展示了Parser和Source类要用到的message包中的消息接口和类,这两个类都实现了接口MessageProducer且每个都有一个MessageHandler。两个类也引用了Message和MessageType类。
设计笔记
在UML类图中,一个带封闭空箭头的虚箭号(比如Parser到MessageProducer和Source到MessageProducer)指出了一个类实现的接口。
图2-4 message包
Parser和Source类都实现了MessageProducer接口,因此每个类必须定义addMessageListener(),removeMessageListener()和sendMessage()方法。与此同时,任何想接收parser和source消息的对象可以分别通过调用parser或source的addMessageListener方法去订阅这些消息。对象不想监听的时候可调用removeMessageListener方法。parser或source每个都能有多个监听器,当它有消息时,可通过调用每一个监听器的messageReceived方法将消息发送出去。
消息生产者(这儿是典型的生产者1/消费者N模式)可拥有一个MessageHandler对象,这样生产者就在addMessageListener()、removeMessageListener()和sendMessage()等方法中调用相应MessageHandler中的方法。换句话说,消息生产者将这些方法交由消息句柄类(MessageHandler)代理。
每次source读了一行新的源代码,在readLine()方法送就会调用消息句柄类的sendMessage()方法,将包含行数和行类容的SOURCE_LINE消息发送到所有监听器。SOURCE_LINE消息报文(body字段)有两个域,一个是lineNumber表示行号,一个是lineText表示行文本。(实际上以数组表示的)
清单2-7 展示了MessageProducer接口
1: /** 2: * <p>能够产生消息的类的公共接口,source, scanner, parser, backend都能产生消息</p> 3: */ 4: public interface MessageProducer 5: { 6: /** 7: * @param listener 要加入的监听器 8: */ 9: public void addMessageListener(MessageListener listener); 10: 11: /** 12: * @param listener 要移除的监听器 13: */ 14: public void removeMessageListener(MessageListener listener); 15: 16: /** 17: * @param message 要向所有注册的监听器广播的消息 18: */ 19: public void sendMessage(Message message); 20: }
清单2-8 扩展了清单2-1,展示了Parser实现了MessageProducer接口,并有一个MessageHandler成员。
1: public abstract class Parser implements MessageProducer 2: { 3: protected static SymTab symTab = null; // 生成的符号表 4: // 代理消息处理类 5: protected static MessageHandler messageHandler = new MessageHandler(); 6: // 此处省略..... 7: public void addMessageListener(MessageListener listener) 8: { 9: messageHandler.addListener(listener); 10: } 11: public void removeMessageListener(MessageListener listener) 12: { 13: messageHandler.removeListener(listener); 14: } 15: public void sendMessage(Message message) 16: { 17: messageHandler.sendMessage(message); 18: } 19: //省略..... 20: }
Source同样实现了MessageProducer接口。清单2-9 展示了它发送SOURCE_LINE消息的readLine方法。
1: private void readLine() 2: throws IOException 3: { 4: line = reader.readLine(); 5: currentPos = -1; 6: //如果读成功,行数+1 7: if (line != null) { 8: ++lineNum; 9: } 10: 11: //每成功读入一行,将当前行数和当前行文本内容以消息方式广播,方便监听器处理。 12: if (line != null) { 13: sendMessage(new Message(SOURCE_LINE, 14: new Object[] {lineNum, line})); 15: } 16: }
所有订阅消息的类必须实现MessageListener接口。留意清单2-10代码,每次消息生产者产生一条消息,它通过调用监听器的messageRecieved()方法,以message作为参数,通知所有监听器。
1: /** 2: * <p>消息监听器公共接口</p> 3: */ 4: public interface MessageListener 5: { 6: /** 7: * @param message 要处理的消息 8: */ 9: public void messageReceived(Message message); 10: }
清单2-11 展示了message包中的Message类构造器。所有发送到监听器的消息都是这个格式。每个消息有一个类型域和一个通用报文域,并提供相应的getter方法(没列出)。
1: package wci.message; 2: 3: /** 4: * <p>消息类</p> 5: */ 6: public class Message 7: { 8: //消息类型 9: private final MessageType type; 10: //消息报文 11: private final Object body; 12: public Message(MessageType type, Object body) 13: { 14: this.type = type; 15: this.body = body; 16: } 17: }
清单2-12 展示了MessageType枚举类型用来表示各种消息类型。
1: public enum MessageType 2: { 3: SOURCE_LINE, SYNTAX_ERROR, 4: PARSER_SUMMARY, INTERPRETER_SUMMARY, COMPILER_SUMMARY, 5: MISCELLANEOUS, TOKEN, 6: ASSIGN, FETCH, BREAKPOINT, RUNTIME_ERROR, 7: CALL, RETURN, 8: }
清单2-13 展示了代理类MessageHandler。如上文所见,消息生产者能创建一个消息句柄然后将工作移交给它(MessageHandler)。消息句柄维护一个消息监听器列表。消息生产者调用sendMessage()方法处理新消息。私有方法notifyListeners()通过调用监听器的messageReceived()方法将消息发给所有监听器。
1: /** 2: * <p>一个句柄类用于替代MessageProducer处理消息</p> 3: */ 4: public class MessageHandler 5: { 6: private Message message; // 消息 7: private ArrayList<MessageListener> listeners; // 监听器列表 8: public MessageHandler() 9: { 10: this.listeners = new ArrayList<MessageListener>(); 11: } 12: public void addListener(MessageListener listener) 13: { 14: listeners.add(listener); 15: } 16: public void removeListener(MessageListener listener) 17: { 18: listeners.remove(listener); 19: } 20: public void sendMessage(Message message) 21: { 22: this.message = message; 23: notifyListeners(); 24: } 25: private void notifyListeners() 26: { 27: for (MessageListener listener : listeners) { 28: listener.messageReceived(message); 29: } 30: } 31: }
设计笔记
MessageProducer和MessageListener接口和MessageHandler类一起实现了观察者模式(Observe Design Pattern)。此模式让消息生产者和消息监听者保持送耦合。
这里的松耦合意思是消息生产者的责任仅句局限于产生消息和通知监听器。消息生产者毋需关心那个是监听器或它们到底如何处理消息,在不修改代码的情况下,它能增加或移除监听器并容纳任意实现了MessageListener接口的监听器。消息生产者或监听器的改动彼此不影响,如果紧耦合将会有问题。
消息生产者类可用MessageHandler辅助类去实际维护和通知监听器。这是代理模式的一个例子(Delegation),一个类让另一个类代替自己处理某些任务。代理模式同样缩小了类的职责且支持送耦合,代理类(此处为MessageHandler)能被任意其他类使用。这比在超类中实现一些功能然后强制子类继承方便多了。通常组合(联合代理类)优于继承。
中间层
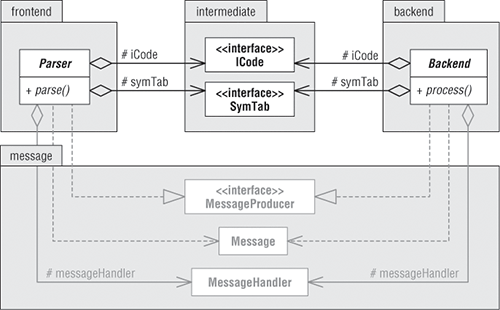
图2-5 展示了frontend,intermediate,backend等包的类图。遵照概念设计,在前端和后端之间的中间码和符号表都是接口。现在只是简单的在intermediate包中定义两个占位接口作为框架组件。backend包中同样定义了抽象类Backend作为框架组件。
图2-5:在intermediate包两边frontend包和backend包对称出现。
上图展示了frontend包中的一个框架对象Parser和backend包中的Backend对象拥有中间码和符号表对象。Parser类,Backend类跟MessageHandler类和MessageProducer接口有相同的引用关系。因此框架具有良好的的对称性。
清单2-14 ICode接口(本章以占位类出现)
1: package wci.intermediate; 2: 3: public interface ICode 4: { 5: }
清单2-15 SymTab接口(本章以占位类出现)
1: package wci.intermediate; 2: 3: public interface SymTab 4: { 5: }
后端
概念设计指出后端将会支持编译器或解释器。如同类图2-5显示的那样,backend包中的Backend类同样是一个消息生产者。与frontend包中的Parser和Source类一样,backend包中的Backend类也实现了MessageProducer接口且将消息处理交由MessageHandler辅助类代理。抽象方法process()需要中间码和符号表的引用(这两个对象产生自Parser)。编译器实现process()为生成代码,而解释器实现process()方法为执行程序。
清单2-16 展示了Backend类中的proces()方法。getter方法和MessageProducer接口相关方法没有展示。
1: /** 2: * <p>框架后端组件类</p> 3: */ 4: public abstract class Backend implements MessageProducer 5: { 6: protected SymTab symTab; // 符号表 7: protected ICode iCode; // 中间码即语法树 8: 9: /** 10: * 处理来自前端Parser产生的中间码和符号表,或编译生成代码或执行 11: * @param iCode 符号表 12: * @param symTab 中间码即语法树 13: * @throws Exception 14: */ 15: public abstract void process(ICode iCode, SymTab symTab) 16: throws Exception; 17: }
到此完成了框架所有组件,满足本章的第一个目标。框架组件与语言无关;到了填充Pascal或其它语言相关内容的时间了。后端组件能支持编译器或解释器。
具体Pascal前端组件
现在框架组件已就绪,将基于框架组件定义一些初期Pascal相关组件。换句话说,这些组件将会是框架组件的子类,提供抽象方法的具体语言实现。
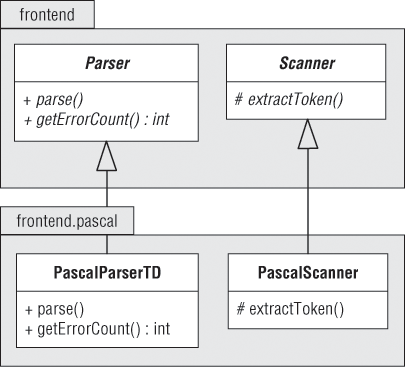
图2-6的类图展示了Parser和Scanner的Pascal实现。Pascal相关前端类定义在frontend.pascal包中。
Pascal Parser
Pascal Parser的初期实现极其简单。类名PascalParserTD表明了源语言和解析类型(Top-Down还是Bottom-Up,具体参见维基百科或龙书)。
清单2-17:类PascalParserTD的初期实现
1: /** 2: * <p>Top-Down模式的Pascal Parser</p> 3: */ 4: public class PascalParserTD extends Parser 5: { 6: public PascalParserTD(Scanner scanner) 7: { 8: super(scanner); 9: } 10: /** 11: *Pascal的解析过程,产生Pascal相关的iCode和symbol table 12: */ 13: public void parse() 14: throws Exception 15: { 16: Token token; 17: long startTime = System.currentTimeMillis(); 18: 19: while (!((token = nextToken()) instanceof EofToken)) {} 20: 21: // 发送解析摘要信息 22: float elapsedTime = (System.currentTimeMillis() - startTime)/1000f; 23: sendMessage(new Message(PARSER_SUMMARY, 24: new Number[] {token.getLineNumber(), 25: getErrorCount(), 26: elapsedTime})); 27: } 28: public int getErrorCount() 29: { 30: return 0; 31: } 32: }
这里的parser()实现了父类的抽象方法。parse方法只干一件事,反复的调用父类的nextToken()方法直到碰到EofToken。目前它忽略token类型。调用nextToken方法强制sanner从source读取token。parser方法也计算全部解析时间并发送一条解析摘要消息。目前getErrorCount方法简单的返回0(因为没有实际的解析过程,也就没有错误了)。
Parser约定其摘要消息格式为:
token.getLineNumber():源程序行读取数
getErrorCount():语法错误数
elapsedTime:耗用时间
所有PARSER_SUMMARY监听器都必须遵从这样的格式。你将会在后续章节进一步完善这个方法。
Pascal Scanner
我们最初的Pascal 扫描器实现还是很简单。PascalScanner实现了父类Scanner的extractToken方法,见 清单2-18
清单2-18:PascalScanner初级实现
1: /** 2: * <p>用于Pascal源程序的Scanner</p> 3: */ 4: public class PascalScanner extends Scanner 5: { 6: public PascalScanner(Source source) 7: { 8: super(source); 9: } 10: /** 11: * 提取source下一个Pascal Token。 12: * @return token 13: * @throws Exception. 14: */ 15: protected Token extractToken() 16: throws Exception 17: { 18: Token token; 19: char currentChar = currentChar(); 20: 21: //文件结束,返回一个特殊EofToken 22: if (currentChar == EOF) { 23: token = new EofToken(source); 24: } 25: else { 26: //将具体构成Token的细节放在Token中是否合适?也就是说Token本身包含逻辑是否合理?有待商榷 27: token = new Token(source); 28: } 29: 30: return token; 31: } 32: }
此处的extractToken实现为后续章节的完善建了一个样板。调用父类的currentChar方法设置当前源字符。前面讲过,当前字符决定该创建什么类型的token(这个很好理解,比如 a=1,碰到a 创建一个id token,接着=是一个操作符,接着数字1是一个数字token)。目前extractToken方法不知道其它token(因为本章没有实现token类型),它碰到文件结束字符EOF创建一个EofToken对象,否则创建一个一般Token对象。
你如何确认后写的每次extractToken()方法就会返回下一个Token?记住每个token的extract方法吞噬源字符且将行中位置定位到Token最尾字符后一个位置。因此下次调用extractToken方法时,调用currentChar()方法将会返回前一个Token后的第一个字符。
你将在下章开发一个完整的Pascal 扫描器。
设计笔记
Java的访问控制修饰符public(公有)、protected(受保护)、private(私有)在维持程序的安全性、可靠性和模块化中扮演重要角色。公有域或方法能够被其它类不受限制访问。受保护的与或方法能够被同包的任何类访问或者不同包的子类访问。包级域或方法(package,也就是不加任何访问控制修饰词)仅能被同一包的其它类访问。私有域或方法只能被同一类中其它元素访问。
你会经常让“受保护”的域和方法能被同一包的其它对象访问,比如前端包。受保护访问在定义具体语言的框架子类尤其有用。每个子类能访问付了的受保护域或方法。
公有方法承担着跨包访问的网关角色。比如Parser的parser方法是公有的,所以能被其它包调用。限制公有方法的数量有助于保持模块化。
顶级类能够有公有或包级控制谁能够访问它们的对象。一个定义在其它中的类可以是私有的。
在程序设计中,尽可能为每个类、域、方法制定制定正确的访问控制修饰符。一条好经验是在可用前提下使用最严格的访问控制。不过,在复杂的程序如编译器和解释器中,随着程序变大,返回去修改现存修饰符很正常。
前端工厂类
前端的组件是语言无关的。你接着将具体语言组件集成到框架中。框架能够支持解析不同的源语言,甚至同一语言的不同解析类型(比如就可以将Pascal的Top-Down和bottom-up解析放到一个框架中)。对任何具体语言来说,Parser和Scanner联系很紧密。
清单2-19 FrontEndFactory工厂类
1: /** 2: * <p>根据具体源语言创建对应的Parser,本书中只有Pascal。</p> 3: */ 4: public class FrontendFactory 5: { 6: /** 7: * 创建Parser 8: * @param language 源语言名称,目前只支持Pascal 9: * @param type 解析器类型,目前只支持top-down类型 10: * @param source 代表源文件的source对象 11: * @return 解析器 12: * @throws Exception 13: */ 14: public static Parser createParser(String language, String type, 15: Source source) 16: throws Exception 17: { 18: if (language.equalsIgnoreCase("Pascal") && 19: type.equalsIgnoreCase("top-down")) 20: { 21: Scanner scanner = new PascalScanner(source); 22: return new PascalParserTD(scanner); 23: } 24: else if (!language.equalsIgnoreCase("Pascal")) { 25: throw new Exception("Parser 工厂: 不支持的语言 '" + 26: language + "'"); 27: } 28: else { 29: throw new Exception("Parser 工厂: 不支持的类型 '" + 30: type + "'"); 31: } 32: } 33: }
静态方法createParser干了所有事情,给定表明源语言和编译类型的字符串参数和一个source参数,它验证语言(本书只有Pascal一种)和类型(只有Top-Down),如果都正确,方法创建一个附带source的PascalScanner对象,接着创建并返回一个附带scanner的PascalParserTD 对象。
设计笔记
工厂类不仅仅是为了方便。因为parser和scanner的铁哥们关系,使用工厂类确保它们成对出现。例如一个Pascal parser总是带着一个Pascal scanner。
使用工厂类也保留了灵活性。如下赋值:
Parser parser = FrontendFactory.createParser( … ); (1)
远比 PascalParserTD parser = new PascalParserTD( … ); (2) 更灵活。因为(2)定死了parser是一个top-down Pascal 解析器(parser)。然调用工厂方法使得我们创建不同类型的解析器而不用改任何代码。
>>>
继续第二章